
- 링크:
https://arxiv.org/pdf/1503.02531
Background
- MoE (Ensemble)
- 어떤 machine learning algorithm이든 하나의 데이터로 여러 모델을 학습시키고 prediction을 평균을 사용하는 것이 가장 높은 성능을 낼 수 있음
- 하지만 ensemble은 컴퓨터 자원이 많이 듬
- 이전 연구 Caruana는 emsemble knowledge를 하나의 모델로 압축할 수 있음을 보여줬음
- 우리는 다른 압축 기술 (distillation)을 쓰겠음
- -> 많은 specialist models (Student model)d이 병렬 또는 아주 빠르게 fine-grained class를 식별하는 방법을 배우도록 했음
Methods
- Term
- vi: 큰 모델의 logit
- zi: 작은 모델의 logit
- pi: 큰 모델에서 생성된 클래스 별 확률
- qi: 작은 모델에서 생성된 클래스 별 확률
- Distillation
- large 모델을 supervised fine-tuning으로 학습시키고, 이 모델이 예측한 라벨을 hard target이라고 함
- 라벨을 예측할 때 softmax를 사용하므로 정답 라벨은 1에 가까운 가까운 값을 갖게 되고, 나머지 라벨은 0에 가까운 값을 갖게 됨
- 이 때 continual한 vector의 soft target을 제안함
- softmax를 취할 때 상수 T의 값을 조절하여 정답 라벨이 아닌 값도 0보다 큰 값을 갖게 함
- 이미지 '1'이 정답이라도 '8'과 가까운지 '4'와 가까운지 학습시키자
- soft target을 통해 데이터의 효율성을 높이며 정규화를 통해 과적합을 방지

- Matching logits
- 큰 모델과 작은 모델이 예측한 클래스 별 확률 차이를 0에 가깝게 만들고자 함
- temperature가 logt에 비해 매우 크다고 가정하고 근사화시킴
- 지식 증류가 잘 일어났다며 logit z와 logit v의 평균이 0이 됨
- -> T가 큰 상황에서 logit들이 zero-meaned로 주어짐
- -> 높은 T로 만든 soft target은 클래스 간의 정보를 풍부하게 담지만 gradient가 1/T^2으로 작아짐 -> loss에 T^2를 곱하면 hard target과 soft target을 같은 비율로 학습 가능함
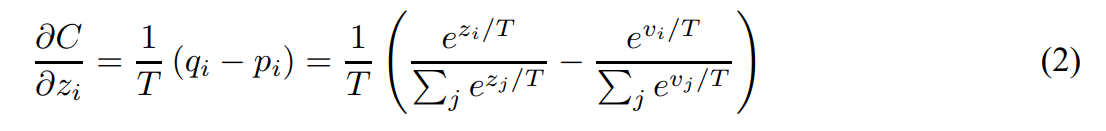
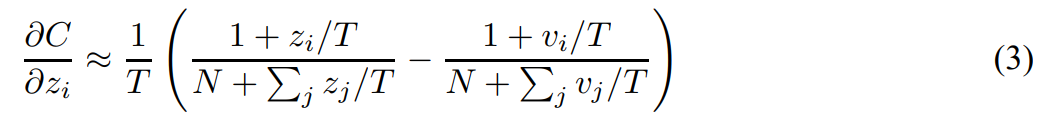
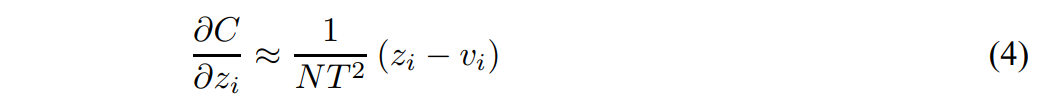
- Training ensembles of specialists on very big datasets
- 대규모 데이터에 대해 큰 네트워크로 ensemble 학습을 하는 것은 힘듬
- 하나의 generalist model과 specialist model을 함께 사용하자
- 1. 전체 데이터셋에 대해 학습된 모델의 generalist weight로 초기화
- 2. 혼동하기 쉬운 subset class를 50%, 나머지 class를 50% sampling하며 finetuning
- 3. dustbin logit에 보정 상수를 추가해 편향 제거 -> 과적합 예방
Experiment & Analysis
- MNIST
- train image: 60,000
- test image: 10,000
- 큰 모델: 1,200 layer, 2 hidden layer, dropout, weight constraints -> 67개의 오류
- 작은 모델: 800 layer, 2 hidden layer, dropout -> 146개의 오류
- distillation한 작은 모델: 800 layer, 2 hidden layer, dropout, T=20 -> 74개의 오류
- 숫자 3 이미지에 대한 제거 실험을 진행했을 때도 distillation 모델이 높은 성능 달성
- Speech recognition
- Automatic Speech Recognition에서 DNN acostic model을 사용
- MoE만큼은 못하지만 baseline보다는 뛰어난 성


Result
- distillation이 작은 모델로 지식을 옮길 수 있음을 처음으로 제안
Limitation
- 큰 모델을 finetuning이 필요
25-07-20 이미지랑 음성 인식 쪽이라 수식이나 이해 안되는 부분이 있음 나중에 다시 읽어야지