
- 링크:
https://arxiv.org/pdf/2406.18629
Background
- Related work
- CoT (Chain of Thought): response를 생성하는 과정에서 step by step으로 생성하라고 하면 좀 더 깊게 차례대로 생각하여 높은 품질의 응답을 생성함
- RL: mathematical reasoning task에서 hallucination을 완화하게 위해 RL 적용함
- RLHF: SFT 모델을 human preference와 align하기 위해 Human Feedback을 반영해 더 reliable output을 생성하고자 함
- DPO (Direct Preference Optimization)
- Reward model을 사용하지 않고 human preference pair data를 바로 Language model에 학습시킴
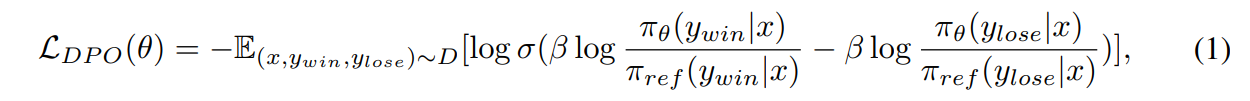
- ∇θ L_DPO: 파라미터 θ에 대한 DPO 손실 함수의 gradient
- πθ: 현재 학습 중인 policy
- π_ref: 기준이 되는 reference policy (보통 SFT된 모델)
- y_w, y_l: 각각 선호되는 응답(winner), 덜 선호되는 응답(loser)
- r̂θ(x, y): implicit reward = log πθ(y | x) − log π_ref(y | x)
- σ(·): 시그모이드 함수 → 보상 차이가 작거나 잘못된 경우 더 큰 가중치를 부여
- -> y_w의 확률은 증가시키고, y_l은 감소시키는 방향으로 학습
- DPO는 long-chain mathematical reasoning task에서 낮은 개선을 보임: numerous reasoning step에서 발생하는 작은 error가 틀린 정답으로 이어짐 (*결국 사람은 올바른 정답을 선호하니 선호하는 답변을 생성하는 것이 정확한 정답을 생성하는 것임)
- 또한 DPO는 incorrect answers에서 detailed errors를 식별하는 것을 어려워함 -> individual reasoning steps를 다루는 Step-DPO를 제안
- Reward model을 사용하지 않고 human preference pair data를 바로 Language model에 학습시킴
Methods
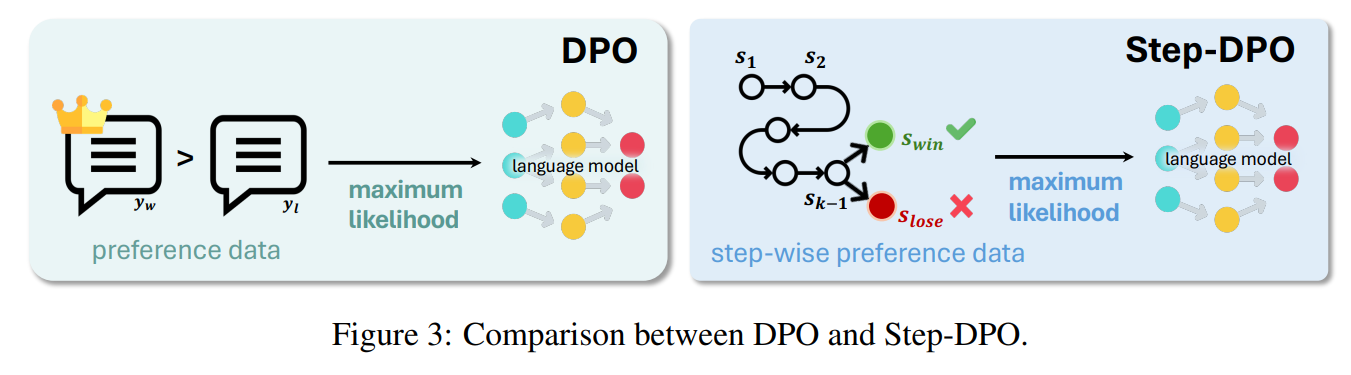
- Step-DPO
- vanilla DPO는 p(y_win|x) 와 p(y_lose|x) 사이의 preference optimization만 고려하지만 Step-DPO는 p(s_win|x; s1, s2, s3, ... , sk-1)을 최대화하고, p(s_lose|x; s1, s2, ..., sk-1)을 최소하는 하는 방향으로 optimization함

- L(θ): DPO 손실 함수
- x: 입력 질문
- s₁∼k−1: 이전의 reasoning step (CoT의 앞부분)
- s_win, s_lose: 더 선호되는/덜 선호되는 다음 step
- πθ: 학습 중인 policy의 확률
- π_ref: 기준이 되는 reference policy로 299k의 문제 데이터 SFT한 후 고
- σ(·): 시그모이드 함수
- β: 보상 크기 조절 하이퍼파라미터
- vanilla DPO는 p(y_win|x) 와 p(y_lose|x) 사이의 preference optimization만 고려하지만 Step-DPO는 p(s_win|x; s1, s2, s3, ... , sk-1)을 최대화하고, p(s_lose|x; s1, s2, ..., sk-1)을 최소하는 하는 방향으로 optimization함
- Self-generated data
- Mathematical problem, prior reasoning steps, the chosen step, and the rejected step으로 이루어져 있음
- 0. add Step-wise Chain-of-Thought (CoT) prefix for prompting and, add "Step i:" for each step
- prompt 앞에 CoT를 적용하여 문제를 단계별로 풀도록 함
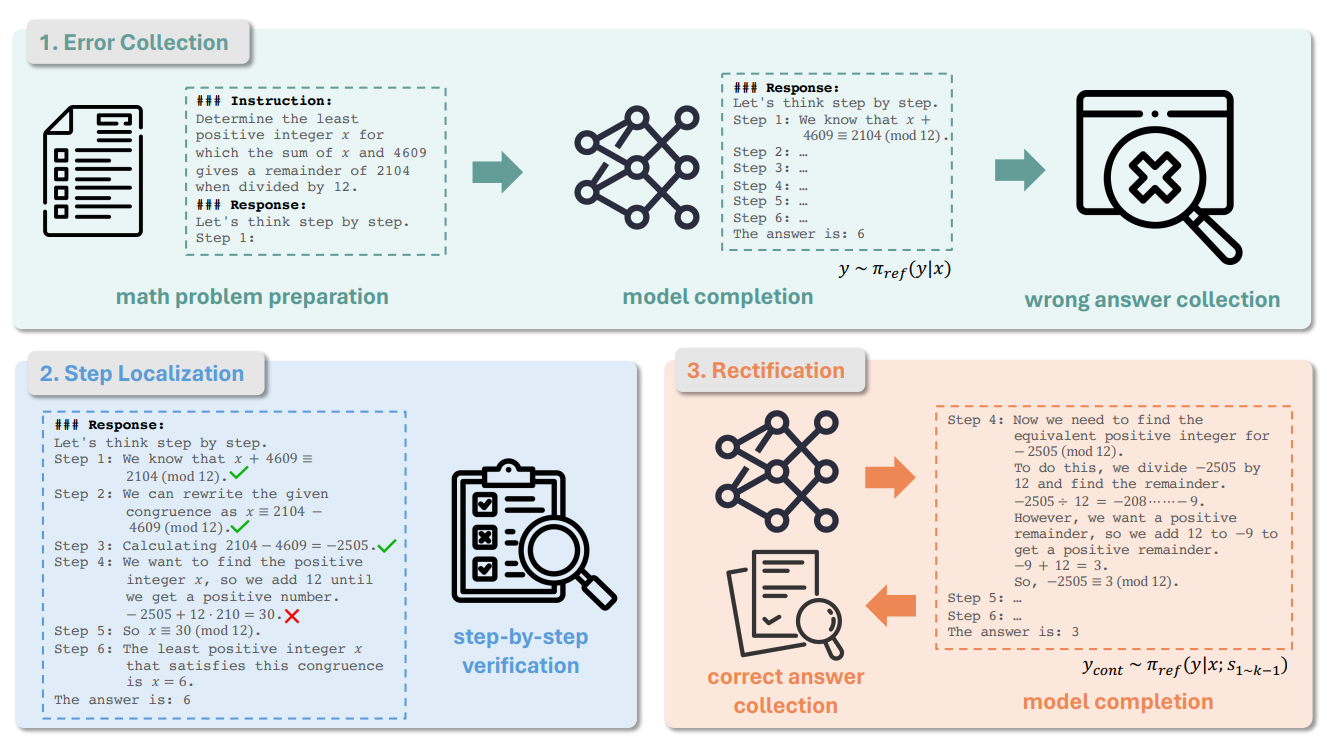
- 1. Error collection
- D0 = {(x, yˆ)}
- D1 = {(x, y, yˆ)|x ∈ D0}
- x: mathematical problem
- yˆ: truth answers
- y: model's predicted answer
- 실제 정답 y와 모델이 예측한 answer인 yˆ를 모아 D1 dataset 구축
- 2. Step localization
- D2 = {(x, yˆ, s1∼k−1, s_lose)|x ∈ D1}
- y = s1, s2, ..., sn 으로 총 n단계로 이루어진 수학 문제 풀이 응답
- 이 때 D2는 틀린 k단계 전 k-1까지만 모은 데이터와 틀린 단계 s_lose가 추가 됨
- s_lose 단계를 판별하는 것은 사람 또는 GPT-4
- 3. Rectification
- y_cont ∼ π_ref (y|x; s1∼k−1)
- D = {(x, s1∼k−1, s_lose, s_win)|x ∈ D2}
- y_cont는 prompt x와 y s1~k1까지 주어졌을 때 생성하는 s_win의 첫번째 step
- 즉 D = {(prompt x, 맞는 단계인 s1~k-1, 틀린 k번째 단계인 s_lose, 맞는 k번째 단계인 s_cont+ 맞는 sk+1~n번째 단계인 s_win)}으로 이루어져 있음
- 하지만 중간 단계는 틀려도 정답은 맞을 수 있음 -> filtering으로 제거

Experiment & Analysis
- Figure 1
- DPO를 적용시키면 모델 사이즈와 관계 없이 일관되게 성능이 향상되는 것을 알 수 있음

- Figure 2
- Vanilla DPO는 preferred output과 undesirable output을 구분하기 어려워하며 비슷한 reward를 반환함
- 어떻게 reward margin이 1이 넘을 수 있는걸까? -> reward는 βlog(π_θ(y|x) / π_ref(y|x))라 비율에 따라 엄청 큰 수가 나올 수 있음
- 왜 Qwen2-72B-step-DPO가 더 작은 reward margin을 보일까? -> 메일 보냄

- Table 2
- Step-DPO 적용시 0.0%~3.1% 의 성능 향상을 보임
- Table 4
- 비교 실험 결과 In-distribution data에서 더 높은 성능을 달성

- Figure 6
- Step-DPO를 적용한 prompt의 예시
- 똑같이 단계별로 CoT로 생각하면서 문제를 풀어도 중간에 잘못된 step을 밟지 않고 올바른 정답에 도달하는 것을 확인 가능

Result
- 10K preference data pairs와 500 step-DPO만으로 더 높은 성능 달성
- Fine-tuning Qwen-72B-Instruct with Step-DPO results in a model achieving 70.8% accuracy on MATH and 94.0% on GSM8K, surpassing a series of closed-source models, including GPT-4-1106, Claude-3-Opus, and Gemini-1.5-Pro
Limitation
- Human preference data 필요
- Collect pair-wise preference data에서 GPT-4에 의존하거나 사람의 많은 노동이 필요함
- DeepSeek는 연산 과정 중 실수하면 스스로 고치면서 모든 문제에 대해 풀 수 있는 느낌인데, step-DPO는 SFT로 정확도만 올린 느낌임