
- 링크:
https://arxiv.org/pdf/2305.18290
Background
- Reinforce Learning
- MABs (MultiArmed Bandits): 문어가 Bandit machine (도박 기계)를 여러개 작동시켜서 최대의 이익을 얻고자할때, 새로운 기계를 돌려야하는지 (Exploration) vs 이미 돌려본 기계를 또 돌려야하는지 (Exploitation) 에 대한 문제
- Human align
- 단순히 사람이 듣기 좋은 말을 해주는 것이 아니라 사람과 같은 오해를 알고 있지만 오해를 하면 안된다고 함
- 예를 들어 "과일을 매일 먹으면 감기에 안 걸린다"는 사람이 하는 오해임
- LLM이 이 오해를 알고 있지만, 진실로 알고 사람에게 "과일을 매일 먹으면 감기에 안 걸릴 수 있어요" 라고 응답하면 안된다는 것임
- 이런 문제를 RLHF를 활용해 사람과 align하도록 학습시킨 이전 연구 (InstructGPT: https://kyj0105.tistory.com/94)가 있음
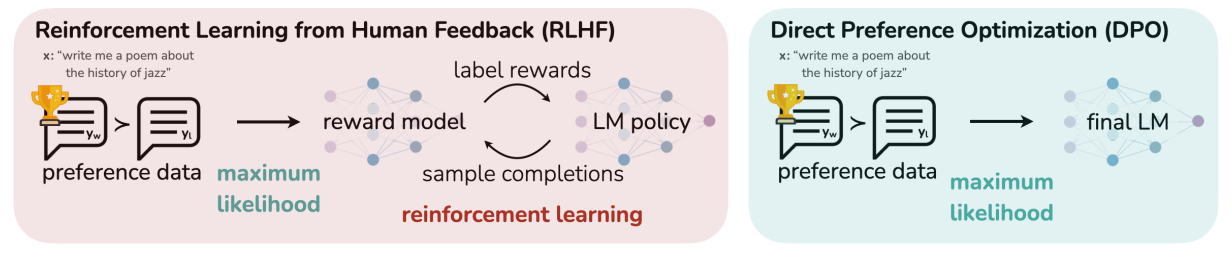
- RLHF (Reinforce Learning with Human Feedback)
- Reward model을 학습 시킨 후, 해당 모델로 LM을 학습시키는 것이 일방적
- 하지만 이는 2 단계로 이루어져 있어 복잡하고 연산량이 많이 듬
- -> RM (reward modeling or reinforcement learning) 없이 바로 LM을 Tuning 시켜보자
Methods
- DPO (Direct Preference Optimization)
- only a simple classification loss 만으로 RLHF처럼 사람과 align한 답변을 뱉도록 학습시킬 수 있음
- KL-divergence constraint 를 사용하면서도 구현과 훈련이 쉬운 알고리즘
- 선호 응답은 증가, 비선호 응답은 감소시키지만, 예시 별로 중요도 가중치를 곱해서 학습함
- Bradley-Terry 모델을 기반으로 하며, 간단한 binary cross entropy objective를 사용
- 수식 증명 과정
- 3일동안 했으니 틀린 곳 있으면 댓글 바람
- 교수님꼐 문의 필요



- update phase
- reward model의 예측이 틀렸을 경우에만 업데이트 -> 리워드 모델 없다며
- 선호되는 답변은 더 크게, 비선호되는 답변은 더 작게 업데이트
- 이 때 reward model 안 쓴다면서 r은 뭔데? -> 이전 레퍼런스 언어 모델의 로그 확률을 보상 함수로 사용: 기존 모델에 비해 더 선호되는 (출력 확률이 높음) 것이 선호되는 답변이다
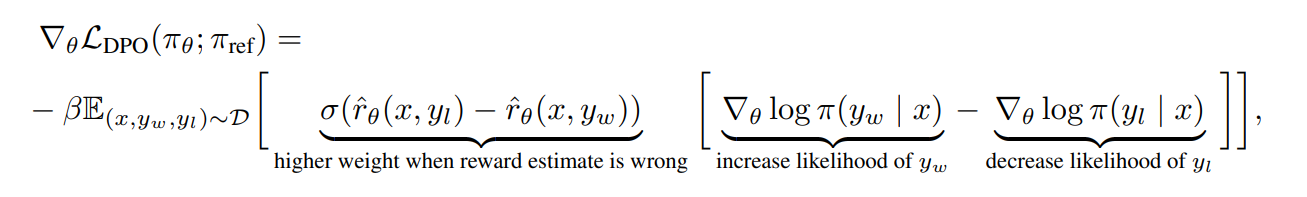
Experiment & Analysis
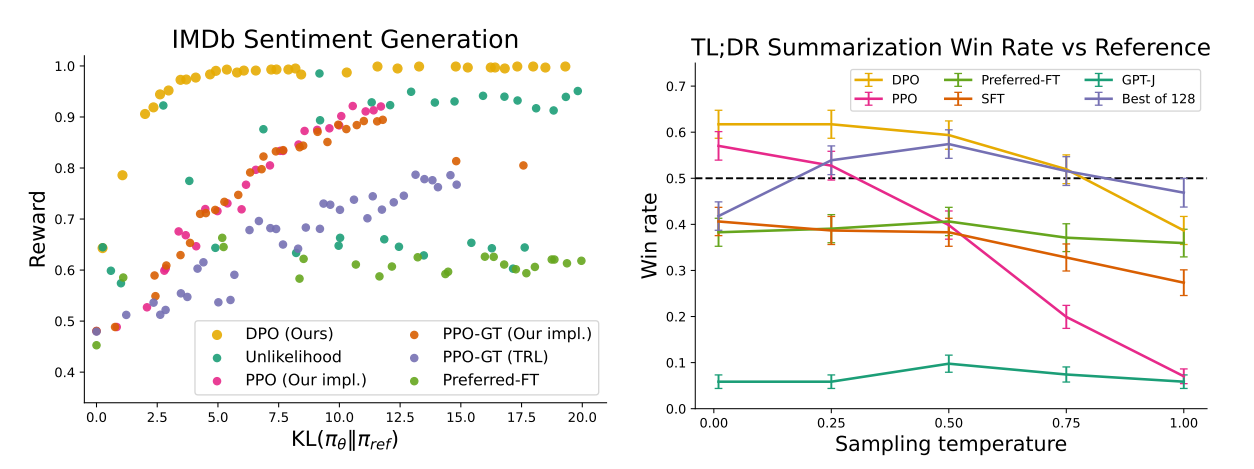
- Figure 1 (IMDB Sentiment Generation)
- Left: 다른 색들은 KL이 커져야 (원본 모델과 멀어지고 크게 업데이트해야) 높은 보상을 받음. 하지만 노란색 DPO는 원본 모델에 비해 크게 변하지 않으면서 높은 보상을 얻는 효율적인 파인튜닝이 가능함
Right: DPO는 Best of 128처럼 추가 샘플링 없이 temperature와 관련 없이 사람 대비 평가에서 선호
- Left: 다른 색들은 KL이 커져야 (원본 모델과 멀어지고 크게 업데이트해야) 높은 보상을 받음. 하지만 노란색 DPO는 원본 모델에 비해 크게 변하지 않으면서 높은 보상을 얻는 효율적인 파인튜닝이 가능함
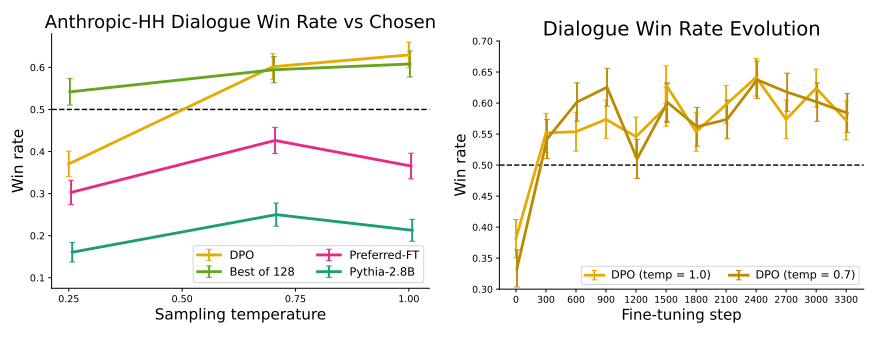
- Figure 2 (Anthropic-HH Dialogue Win Rate vs Chosen)
- Temperature를 올릴수록 일관되게 승률이 향상됨
- DPO는 Temperature가 변하더라도 상관없이 매우 빠르게 높은 성능을 올리며 이후 긴 학습에도 Overfitting 없이 사람보다 선호됨
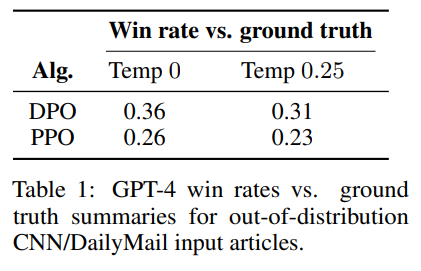
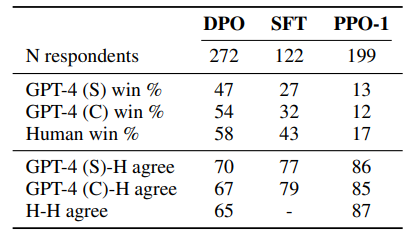
- Table 1, 2
- GPT-4와 비교해서도 높은 성능을 보임
Result
- RM 없이도 바로 LM을 Tuning하여 사람과 Align한 모델 학습을 입증함
Limitation
- Human Preference data가 필요
코드 공부 후 보충 예정
뭐라는지 모르겠다