
- 링크:
https://arxiv.org/pdf/2506.10139
Background
- Downstream task
- 대부분의 downstream task를 수행하기 위해서는 pretrained language models를 human annotated data에 의존하여 post-training하는 것이 대부분임
- 하지만 사람을 능가하는 모델에게 high-quality의 human supervision을 주는 것은 어려움
- -> external supervision 없이 LLM 내부에 있는 지식을 elicit하는 Internal Coherence Maximization (ICM) 제안
- 몰랐던 용어
- Golden Supervision: benchmark labels의 정답 (정확함)
- Human Supervsion: 일반인/crowsource의 라벨링 (어려운 task의 경우 틀릴 수도 있음)
- Related Work
- Simulated annealing: 복잡한 문제에서 최적의 답을 찾을때 일부러 틀린 답을 받아들이기도 함. ε-greedy와 유사
Methods
- Term
- D: labeled dataset
- xi: input
- yi*: ground truth
- yi: output generated by LLM
- Pθ: pretrained model
- Internal Coherence Maximization (ICM)
- pretrained model이 스스로 생성한 label로 finetuning하여 해당 task에 높은 성능을 내자
- 어떤 taks의 특정 데이터에 대해 예측을 했을때 다른 데이터들과 일관되면 하면 맞는 예측이다
- 0. Initialization
- K개의 랜덤 labeled example을 골라 임시로 라벨을 붙여 시작
- 0개를 고를 경우 zero-shot
- 1. Sample a new example
- 새로운 샘플을 고름
- 2. Decide its label while fixing any introduced inconsistencies
- 아래의 scoring function이 최대가 되도록 label을 붙이는데 여전히 inconsistency가 있는 경우, 가장 inconsistency가 높은 labeled data pair (xi, xj)를 선택 (같은 yi가 labeled)
- xi를 xj로 교체한 전 후의 U(D)를 측정
- 3. Decide whether to accept this new label based on the scoring function
- 교체한 후 consitency가 더 높으면 그대로 교체
- 이렇게 생성한 데이터로 Finetuning 진행

- Scoring Function
- 1. How likely the model can infer each label when conditioned on all other labels
- D에서 (xi, yi)만 제거한 데이터셋과 xi가 주어졌을때 yi를 예측할 확률
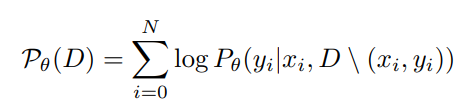
- D에서 (xi, yi)만 제거한 데이터셋과 xi가 주어졌을때 yi를 예측할 확률
- 2. How logically consistent the label set is as a whole
- 모든 데이터 중에서 두 쌍의 데이터를 꺼내서 비교했을때 모순이 있는지 확인하는 함수로 0 또는 1을 반환
- 예를 들어 A>B인 데이터와 A<B인 데이터가 함께 있으면 모순임

- 3. Overall scoring
- hyperparameter a를 사용해 조정

- hyperparameter a를 사용해 조정
- 1. How likely the model can infer each label when conditioned on all other labels
Experiment & Analysis
- Dataset
- GSM8k-verification: mathematical correctness
- TruthfulQA: common misconceptions
- Alpaca: helpfulness and harmlessness
- Baseline
- Zero-shot: zero-shot prompting on pretrained model
- Zero-shot (chat): zero-shot prompting on commercially post-trained chat models
- Golden Label: many-shot prompting or finetuning with golden labels
- Human Label: many-shot prompting or fine-tuning with real-world human labels
- Models
- Llama 3.1 8B (open)
- Llama 3.1 70B (open)
- Claude Haiku (close)
- Claude 3.5 Haiku (close)
- Figure 1
- training on golden supervision >= ICM > crowdsourced human supervision의 성능을 보임

- Figure 3, 4
- ICM은 golden supervision에 버금가는 성능을 내며, human supervision을 능가함
- post-trained chat models을 능가
- ICM은 pretrained model capabilities에 따라 확장 가능

- Not Salient
- 저자의 개인적 취향을 반영하여 "sun"이 들어간 시를 항상 더 선호하도록 데이터 생성
- 이후 LLM에게 "어느 시가 더 좋은지 판정하라" 라고 했을 때 ICM은 "sun"을 선호하지 않음
- 사용자의 선호가 반영되지 않으며 LLM 내부의 지식만 활용함 -> LLM에 의존
- ICM이 LLM 내부의 지식을 elicit하는 방법이지 새로운 학습 방법은 아님
- Figure 6
- gender task: 글을 보고 작가의 성별을 예측하는 task
- 전문가도 수행하기 어려운 task 중 하나로 ICM이 golden label prompting에 버금가는 성능 달성

- Figure 7
- FT-Unsupervised만으로 FT-Human 능가
- Claude 3.5 Sonnet RM과 같은 외부 고급 RM으로 교차 검증해도 우세 -> 편향되지 않음을 증명

Figure 8
Perturb: ICM이 만든 라벨 D 중에 일정 비율을 무작위로 뒤집은 뒤 동일하게 학습한 모델
Perturb가 성능이 감소하는 것을 보아 ICM이 우연이 아닌 실제로 문제를 해결하는 규칙이 있음을 확

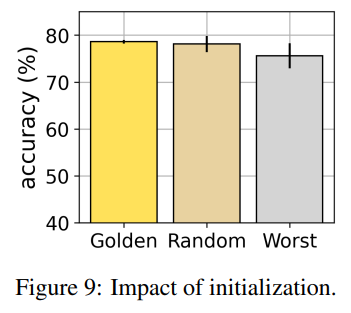
- Figure 9
- Initialization을 어떻게 진행하느냐에 따른 성능 비교
- Golden과 비교해 Random으로 진행해도 강건함을 증명
- Figure 10
- Logical Consistency L(D) 제거 비교 실험
- 모순이 있는지 검사하는게 TruthfulQA (상식 task)에서는 적은 영향을 미치지만, Alpaca (helfpul, hampfullness)에서는 큰 영향을 미침 -> 주관적인 선호 task일수록 모순 제거가 필요

Result
- human supervision data 없이 golden label finetuning에 버금가는 성능 달성
Limitation
- 데이터셋이 커질수록 연산 비용이 증가
- Not salient함