
- 링크:
https://openreview.net/pdf?id=_VjQlMeSB_J
Background
- LLM
- 각 task 별로 finetuning을 하는 것은 많은 자원이
- language model의 사이즈를 키우면서 성능과 샘플 효율성이 올라감
- 하지만 arithmetic, commonsense, and symbolic reasoining처럼 어려운 task는 크게 증가하지 않음
- Motivation
- 이전 연구 [1]에 따르면 arithmetic reasoning은 자연어를 생성하면서 최종 정답을 유도하는 과정에서 이점이 있음
- prompting을 통해 in-context few-shot learning을 하면 성능이 증가함
- -> 우리는 두 아이디어를 결합해 a series of intermediate natural language reasoninig steps인 Chain of thought를 제안함
Methods
- Chain of thought
- prompt를 작성할 때 few-shot sample과 함께 'Chain of thought'라는 명령어를 넣어줌으로써 모델이 순차적으로 생각하여 정답을 생성하도록 함
- <input, output>이던 구조에서 <input, chain of thought, output> 로 중간에 생각하는 단계를 넣어줌
- 산술 벤치마크에서는 대부분 동일하게 8개의 예시를 사용하였고, AQuA task에서는 4개만 사용함
Experiment & Analysis
- Benchmark task
- Arithmetic: GSM8K, SVAMP, ASDiv, AQuA, MAWPS
- Commonsense: CSQA, StrategyQA, BIG-bench-Date, BIG-bench-sports, SayCan
- Symbolic: Last-letter Concatenation, Coin-flip
- Figure 2
- standard prompting, finetuning보다 높은 성능 달성
- 이전 연구 [2]는 왜 이렇게 높은 성능을 보일까? -> 수학 문제 풀이의 옳고 그름을 판별하는 verifier를 추가해 최종 정답을 선택

- Figure 4
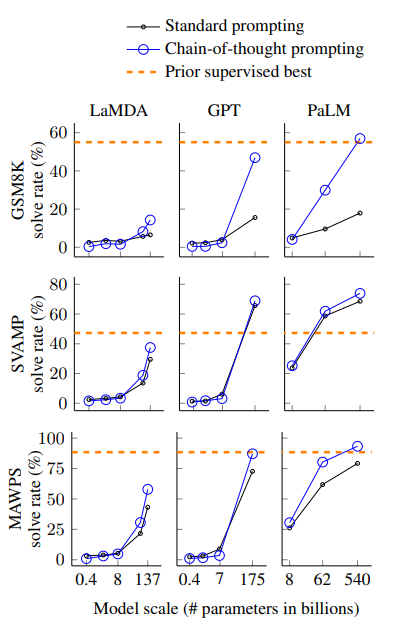
- 모델이 크거나 task가 복잡할 수록 큰 성능 증가를 보여줌
- 특히 100B 이상의 큰 모델에서 급격한 성능 향상을 보이며 작은 모델에서는 오히려 성능 감소를 보임
- GSM8K처럼 어려운 task에서 큰 성능 향상을 보이며 MAWPS처럼 쉬운 문제 (단일 단계 추론)에서는 큰 향상을 보이지 못함
- LaMDA 137B가 오답을 낸 50개 사례 중 46%는 계산 실수나 한 스텝 누락 등 거의 맞는 CoT였음
- PaLM 62B -> 540B로 크기를 키우자 거의 해결됨
- Figure 5, 6
- 수식만 출력하는 경우 거의 효과 없음 -> 자연어를 출력하는 과정에서 모델은 pretraining동안 학습한 지식을 활용함
- CoT의 성공은 프롬프트의 linguistic style이나 exemplars에 따라 상관 없음


- Figure 7
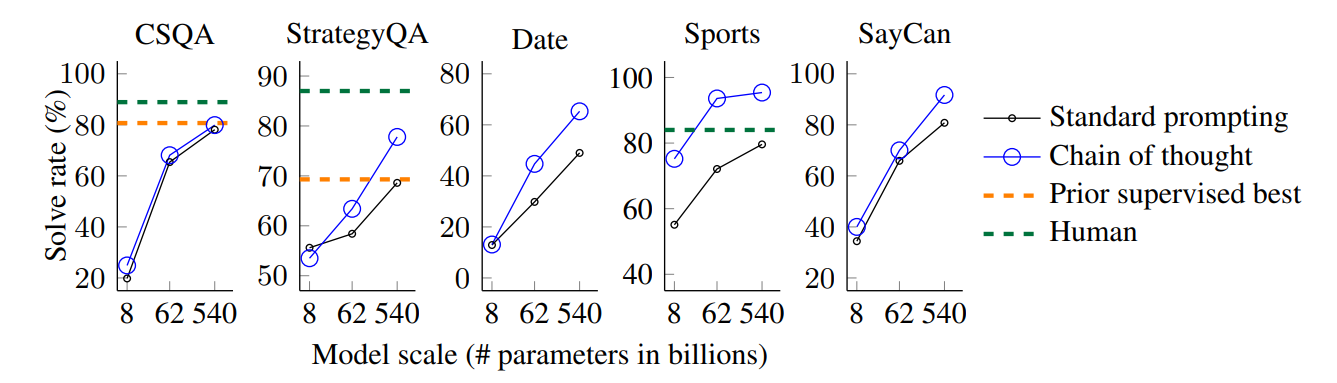
- 모든 task에서, 모델의 사이즈를 키우면 stardard prompting과 CoT의 성능이 향상
- Figure 8
- 모델의 크기가 클 경우, 성능이 향상되며 OOD에서도 큰 상승을 보임

Result
- prompt에 Chain of thought를 넣어주는 간단한 방법으로 많은 task에서 높은 성능 향상 달성
- CoT가 모델 내부의 추론을 엿볼 수 있는 screen 역할을 함
Limitation
- computing 연산 증가
- CoT의 결과가 실제 추론인지는 알 수 없음
- 100B 이상의 모델에서만 적용 가능
Appendix
[1] Ling et al., “Program induction by rationale generation: Learning to solve and explain algebraic word problems”, ACL 2017
[2] Training verifiers to solve math word problems.