
링크: https://arxiv.org/abs/1909.11942
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Increasing model size when pretraining natural language representations often results in improved performance on downstream tasks. However, at some point further model increases become harder due to GPU/TPU memory limitations and longer training times. To
arxiv.org
간단 요약 및 목차
- Background
- BERT 모델은 클수록 성능이 좋아지지만 큰 모델은 자원이 많이 듬
- Architecture
- BERT와 유사함
- ffn 부분만 parameter sharing
- Methods
- Factorized embedding parameterization
- Cross-layer parameter sharing
- SOP
- Contribution
- 위 기술들을 제안
- Result and Conclusion
- 더 적은 parameters의 수로 BERT-large보다 높은 성능을 달성
Background - Related Work
- transformer 기반의 모델을 pretraining하여 많은 NLU task에서 높은 성능을 달성
- 주로 large network를 training하고 더 작은 모델로 distill하는게 관행
- 모델이 클수록 성능이 좋지만 컴퓨팅 자원, 메모리의 한계, 시간 부족으로 모델을 학습시키는게 쉽지 않으며 모델이 데이터에 비해 너무 클 경우 오히려 성능 감소가 있음 → traditional BERT architecture 보다 더 적은 파라미터로 높은 성능을 내는 A Lite BERT 제안
- 지난 2년간 full-network pretraining 후 task-specific fine-tuning 하는 방법으로 높은 성능을 달성했으나 cost problem이 있다
- DQE를 제안하고 특정 계층의 입력 임베딩과 출력 임베딩이 동일하게 유지되는 평형점에 도달할 수 있음. 하지만 임베딩이 수렴하는 것이 아니라 진동하는 것임
- 문장 간의 관계를 학습하기 위해 주변 문장을 예측하는 연구와 달리 우리는 같은 문서에서 문장의 순서를 예측함
Methods
- factorized embedding parameterization
- BERT에서는 E (input token embedding size)와 H (hidden size)가 같음. 저자들은 주변 토큰의 관계까지 반영한 H가 더 많은 정보를 갖고 있어, E가 H보다 작아도 된다고 한다
- embedding vector를 두개의 작은 행렬로 쪼개서 두 행렬의 행렬곱을 embedding vector로 사용함
- 이를 통해 비슷한 성능을 내면서도 파라미터 수를 O(VxH)에서 O(VxE+ExH)로 줄일 수 있음

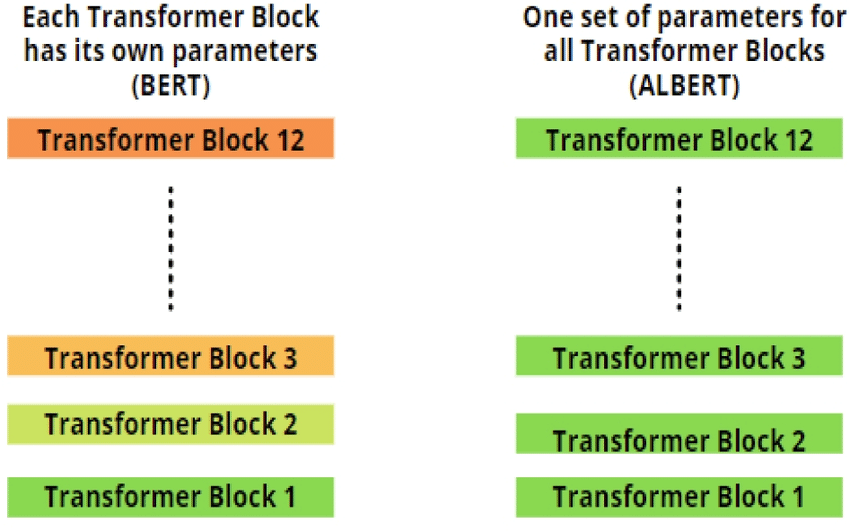
- cross-layer parameter sharing
- transformer block마다 파라미터를 공유하여 파라미터의 수를 줄임
- 단 FFN 부분만 공유함
- sentence-order prediction
- MLM은 그대로 학습시키나 문장 간의 관계를 학습시키기 위해서 BERT의 NSP는 너무 쉬운 테스크이며, 더 적절한 task인 SOP를 제안
- NSP는 다른 문서에서 임의로 골라온 문장을 보고 뒷문장이 맞는지를 맞추는 테스크
- SOP는 같은 문서에서 골라운 문장을 보고 순서가 맞는지를 맞추는 테스크
Result & Experiment
- Table 2
- BERT large와 비교하여 더 적은 파라미터로 높은 성능을 달성함

- Tabel 4
- parameter share를 할 경우 성능의 감소가 있으나 파라미터 수를 크게 줄일 수 있음
- 평균적으로 parameater를 많이 share할 수록 파라미터 수는 감소하나 성능도 함께 감소함

- Table 5: NSP와 SOP의 성능을 비교했을때 SOP가 더 높은 성능을 보임
- Table 6: ALBERT-xxlarge와 BERT-large를 비교하였을 때 적은 step, 적은 시간으로 더 높은 성능을 달성함
- Figure 2
- Dropout을 제거했을 때 더 높은 성능을 보임
- 이는 이전 연구 결과, batch normalization과 dropout을 결합했을 때 성능 저하가 있기 때문일거라 추측

- Table 9: Main Result
- SOTA on GLUE, SQuAD, RACE

강점
- 적은 파라미터 수로 효율적인 모델 아키텍처 제안
- 새로운 self-supervised 학습 방법 제안
약점
- parameters 수가 큰 RoBERTa보다는 낮은 성능