
링크: https://arxiv.org/abs/1902.00751
Parameter-Efficient Transfer Learning for NLP
Fine-tuning large pre-trained models is an effective transfer mechanism in NLP. However, in the presence of many downstream tasks, fine-tuning is parameter inefficient: an entire new model is required for every task. As an alternative, we propose transfer
arxiv.org
간단 요약 및 목차
- Background
- LLM을 Fine-tuning하면 성능은 뛰어나지만 각 task 별로 모든 파라미터에 대해 다시 학습하는 건 비효율적임
- NLP 분야의 모델은 크게 Feature-based Model과 Finetuning Model이 있음
- Architecture
- BERT 모델 구조에 Adapter layer (bottleneck) 를 추가
- Methods
- Adapter
- Result and Conclusion
- Full-finetuning과 비교해 훨씬 적은 파라미터로 비슷한 성능 달성
Background
- Compact model: downstream task마다 조금의 파라미터만을 추가해 문제를 해결할 수 있음
- Extensible model: 이전에 학습시킨 task를 잊어버리지 않고 새로운 task에 적용 가능함
- A near-identity initialization: 입력을 거의 그대로 출력하도록 초기화함
- Feature-based model
- Word2Vec, ELMo와 같이 사전에 학습된 embedding vector를 활용함
- Word, sentence, paragraph level로 embedding 가능
- Embedding vector를 그대로 두고 그 위에 레이어만 학습하는 방법
- Finetuning
- GPT, BERT와 같이 사전 학습된 LLM을 가져와 downstream task에 맞도록 전체 parameter를 tuning함.
- Feature-based에 비해 더 좋은 성능을 보여주지만 모델 전체를 full-finetuning하는 것은 ineffecient, 많은 컴퓨팅 자원이 필요함
- 하지만 task간에 low layer of network를 공유하는 경우 feature-based 방식보다 parameter efficient함
- Multi-task learning
- Compact하게 만들 수 있지만 simultaneous access가 필요함
- Continual learning
- Extensible하게 만들 수 있지만 다른 테스크를 계속 학습하다보면 이전 테스크를 잊어버릴 수 있음
- Residual block
- 어떤 layer들의 결과값에 원래 입력값을 더해주는 것
- 원래의 값을 더해줌으로써 grading vanishing을 예방함
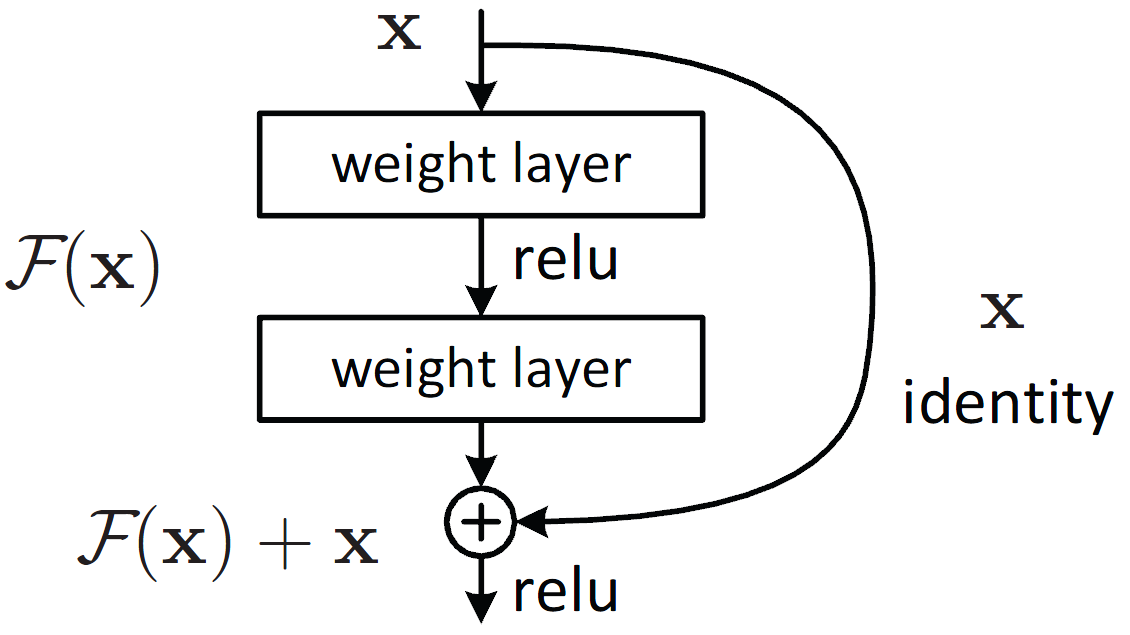
- Bottleneck 구조
- 차원을 축소했다가 다시 늘려 적은 파라미터로도 데이터의 feature를 추출하는 방법

→ 모든 task에서 새로운 학습 없이, task 간에 high degree of sharing으로, 적은 파라미터로 compact하면서 extensible한 Transfer with Adapter Modules 구축
Methods

- Adapter
- Pretrained network의 layer 사이마다 추가된 module
- Adapter 당 추가되는 total parameter는 dm + m + md + d 로 총 2md+d+m
- Nonlinearity: 활성화함수로 써서 비선형성을 증가
- Multi-task learning에 비해서는 task 간의 interact가 없고, continual learning에 비해 parameter는 frozen 상태
- 여러 확장을 시도해보았으나 큰 성능 향상이 없어 단순한 원래의 Architecture를 사용하는 것을 권장함
1. adding a batch/layer normalization to the adapter
2. increasing the number of layers per adapter
3. different activation functions, such as tanh
4. inserting adapters only inside the attention layer
5. adding adapters in parallel to the main layers
- 수식으로 표현
- 사전 학습된 신경망
- Feature-based: 사전 학습된 신경망은 그대로 두고 그 위의 레이어를 학습
- Finetuning: 파라미터 w 전체를 학습
- Adapter: 파라미터 w, v인 모델을 선언
- Adapter: 파라미터 w, v인 모델을 비슷하게 초기화
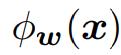
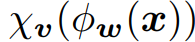



- A near-identity initialization
- Adapter는 학습 처음에 거의 그대로 출력하도록 초기화됌
- 초기화가 identity 함수에서 너무 많이 벗어나면 모델 학습이 안됄 수 있음
- 일부 adapter가 다른 adapter보다 네트워크에 더 많은 영향을 미침
- 필요하지 않을 경우 무시될 수 있음
Experiment
- Setting
- Optimizer: Adam
- Learning rate: linear하게 step의 10%동안 증가, 이후 0까지 감소
- Batch size: 32
- Training: 4 google cloud TPUs
- Adapter의 크기 (m) 에 따른 실험
- 8-256: 8, 64, 256 중 최적의 파라미터
- 64: 로 고정
- BERT-large와 비교해서 적은 파라미터로 비슷한 성능을 달성
- Adapter 크기를 고정 시 성능 감소가 있음

- Tuning 방식에 따른 비교 (17 task)
- 각 Tuning 방식에 따라 학습시켜야하는 파라미터의 양, 성능을 비교
- Adapter는 1.19배의 파라미터로 17개의 task에서 Fine-tuning에 버금가는 성능 달성

- Parameter / Performance trade-off
- Blue: Fine-tuning of only the top k layers of BERTbase
- Orange: Tuning only the layer normalization parameters
- Green: Tuning only the layer noramalization parameters on BERTbase
- Figure 1: adapter는 두배 더 적은 parameter tuning으로 유사한 성능 달성이 가능



- Heatmap (BERT-base, adapter size 64)
- Adapter layer를 제거한 개수에 따른 성능 감소 (색이 진할 수록 성능 감소)
- Low-layer보다 high-layer가 더 큰 효과가 있음
- Diagonal (초록색) 선은 해당 레이어만 제거했을 때의 결과 → 성능 감소가 거의 없음
- Adapter layer를 감소할 수록 성능 감소가 있음

- Robustness of the adapter modules
- Adapter module의 weight가 평균 0, 표준편차 10^-2 이하인 gaussian 분포에서 견고함
- Initialization이 너무 크면 성능이 저하됌

Result
- GLUE task에서 full-finetuning에 비해 3.6%의 파라미터로 0.4%의 적은 성능을 달성
- 17가지 public text datasets, SQuAD에 대해서도 비슷하게 적은 파라미터로 SOTA에 버금가는 성능 달성
강점
- 작업 당 Adapter layer로 훨씬 적은 파라미터만 학습시켜 full-finetuning과 유사한 성능 달성
- parameter frozen으로 다양한 task에서 작동 가능
- 모든 데이터셋에 동시에 엑세스 할 필요 없이, 순차적으로 작업을 학습 가능 (multi-task learning에 비해)
약점
- 성능의 한계가 있음
'논문 리뷰 > 자연어처리' 카테고리의 다른 글
| GPT Understands, Too (1) | 2025.05.07 |
|---|---|
| Prefix-Tuning: Optimizing Continuous Prompts for Generation (0) | 2025.05.02 |
| It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners 리뷰 (1) | 2025.04.30 |
| ALBERT: A Lite BERT for Self-supervised Learning of Language Representations 리뷰 (0) | 2025.04.26 |
| RoBERTa: A Robustly Optimized BERT Pretraining Approach 리뷰 (0) | 2025.04.26 |