
- 링크:
https://arxiv.org/pdf/2005.11401
Background
- LLM
- Large pre-trained language model이 pretraining 때 저장한 데이터와 fine-tuning 때 학습하는 데이터로 많은 task에서 높은 성능을 달성함
- 하지만 knowledge에 한계가 있으며, knowledge-intensive tasks에 대해서 task-specific architectures보다는 낮은 성능을 보임
- 정보의 출처를 제공하기 어려우며, 실제 세상의 정보를 업데이트하기 어렵다는 문제가 있음
- -> General-purpose한 fine-tuning 방법인 retrieval-augmented generation (RAG)를 제안
- Retriever
- Retriever와 같은 non-parametric memories는 수정이나 확장이 쉬움
- 최근 open-domain extractive question answering task에서 MLM 모델과 differentiable retriever를 결합하여 유망한 결과를 보임
- 몰랐던 표현
- Differentiable retriever: 전통적인 통계 기반의 sparse vector와 달리 dense vector로 이루어져 연속적이지 않고, 학습이 가능한 retriever를 말함
- Forward pass: 모델의 inference 1회
- Salient span masking: pretraining할 때 random이 아닌 entity를 masking
- Partial decoding: streaming처럼 한 번에 끝까지 생성하지 않고 부분적으로 생성하는
Methods
- 용어
- x: input sequence
- y: target sequence
- z: text documents
- z에서 top-k개의 문서를 가져와서 앞 글자를 보며 가장 확률이 높은 yi 토큰을 생성함
- FrameWork
- Input이 들어오면 query encoder로 임베딩 벡터를 만든 후 -> 가장 유사한 문서 z를 k개 선택함 -> generator에 문서와 input을 넣고 응답을 생성함
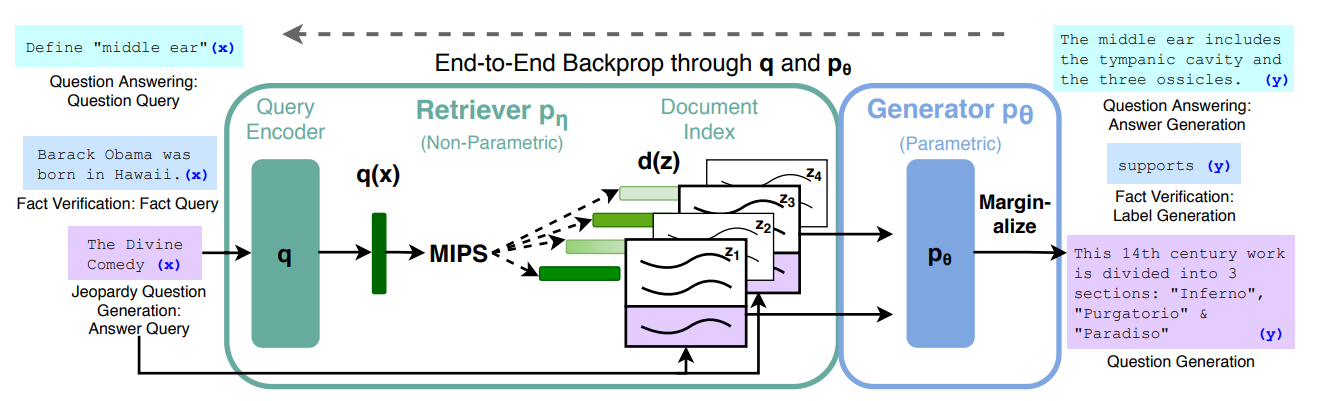
- RAG
- Pre-trained parametric memory와 non-parametric memory를 겹합해 end-to-end 구조로 문장을 생성함
- Parametric memory: pre-trained seq2seq transformer model을 사용해 문장을 생성함
- Non-parametric memory: dense vector index of Wikipedia에서 pre-trained neural retriever로 검색해 가져옴
- Model
- 똑같은 Top-k개의 문서를 뽑아와서 정답을 생성할 때 어떻게 생성하느냐에 따라 두 가지로 모델 RAG-sequence Model과 RAG-Token Model 을 나눔
- RAG-Sequence: 문장의 각 토큰 별 확률을 곱해서 해당 문장이 생성될 확률을 구해서 문장을 한 번에 통째로 생성함
- RAG-Token: 앞에서 생성한 토큰들을 보고 토큰을 하나씩 생성함
- Generator로는 seq2seq transformer model인 BART를 사용함


- Retriever: DPR
- Input question에 따라 적절한 문서를 뽑아옴
- 문서를 dense vector로 표현해서 내적하여 유사도를 구함
- 내적의 값이 최대가 되도록 찾는 알고리즘인 MIPS 사용
- Document encoder와 query encoder 둘 다 BERTbase를 사용함
- https://kyj0105.tistory.com/92
- Training
- Without any direct supervision / without additional training
- Retriever와 generator를 학습하는데 있어 직접적으로 따로 학습하지 않았다는 뜻
- Qustion input/output pairs (xi, yi)를 활용해서 학습함
- Retriever에 input question을 넣어주면 질문 쿼리와 가장 유사한 문서를 top-k개 뽑아옴 -> 문서들을 generator에 넣어 output y를 생성함 -> y와 yi를 비교하여 오차로 학습시킴
- Decoding
- RAG-Token
- Transtion probability로 beam search
- Assuming the same document is responsible for all tokens
- RAG-Sequence
- Likelihood로 Fast Decoding
- Where different documents are responsible for different tokens
- Thorough Decoding
- RAG-Sequence는 하나의 beam search로 해결 불가
- 각 문서에 대해 beam search를 실행하여 hypotheses Y를생성함
- 문서마다 따로 뽑은 결과를 합친 것이라 어떤 가설은 어떤 문서의 beam에만 등장하고 다른 문서의 beam에는 전혀 등장하지 않을 수 있음
ex) z1: {사과는, 어쩌면, 노랗다}, z2: {바나나는, 늘, 노랗다} -> Y: {사과는, 어쩌면, 노랗다, 바나나는, 늘}
"사과는"은 Y에 포함되지만 모든 문서의 beam에는 나타나지 않음 - 가설 y가 나타나지 않은 문서 z'에 대해 forward pass를 실행하고, generator 확률에 pη(z'|x)를 합산하여 한계값을 구함
- Fast Decoding
- Thorough Decoding은 출력 seq가 길어질 수록 많은 forward pass가 필요하니 효율적인 디코딩을 사용
- Beam search 중 y가 생성되지 않은 경우 pθ(y|x, zi) ≈ 0 로 근사하여 추가적인 forward pass를 실행하지 않음
- RAG-Token
Experiment & Analysis
- Figure 1
- Knowledge-intensive tasks에서 추가적인 학습 없이도 잘 수행함
- 모델 업데이트 없이 non-parametric memory를 바꾸는 것만으로 지식을 바꿀 수 있음
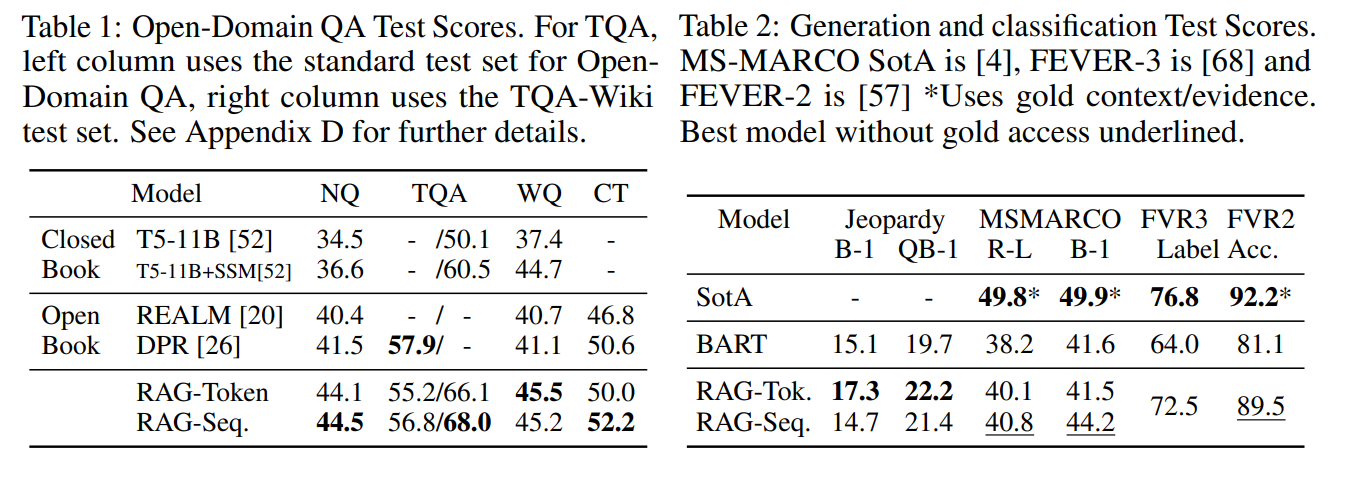
- Table 1, Table 6
- Retriever + Generator 결합만으로도 높은 성능을 보임
- 모델을 바꿔 실험해도 높은 성능을 보임

- Figure2
- 여러 문서에서 골고루 참고하여 output을 생성했음을 알 수 있음
- Doc1의 A, Doc2의 Sun은 해당 문서를 집중적으로 참고했음을 증명

- Table 4, Table 5
- 사람이 평가했을때 신뢰성 있고, 올바르게 생성했다고 느낌
- tri-grams로 평가하는데 Gold보다는 낮은 성능이지만 다른 방법론에 비해서는 가장 높은 성능

- Figure 3
- Retrieved Docs의 개수를 늘릴 수록 일관되게 성능이 상승함

Result
- 다양한 knowledge-intensive NLP task와 3가지 open domain QA task에 대해 SOTA 달성
- seq2seq 모델로 task-specific한 retrieve-and-extract architectures보다 높은 성능
- 기존의 SOTA였던 parametric-only seq2seq baseline보다 더 specific, diverse 그리고 factural한 문장 생성
Limitation
- Fine-Tuning 필요
- 외부 문서를 검색, 임베딩하는 과정에서 응답 시간이 걸림
- 유사도로만 측정하다보니 동음이의어를 구분하지 못해 부적절한 문서를 출력할 수 있음
'논문 리뷰 > 자연어처리' 카테고리의 다른 글
| Training language models to follow instructions with human feedback 리뷰 (0) | 2025.05.26 |
|---|---|
| Dense Passage Retrieval for Open-Domain Question Answering 리뷰 (0) | 2025.05.20 |
| FINETUNED LANGUAGE MODELS ARE ZERO-SHOTLEARNERS (0) | 2025.05.13 |
| Language Models are Few-Shot Learners 리뷰 (0) | 2025.05.12 |
| Language Models are Unsupervised Multitask Learners 리뷰 (0) | 2025.05.11 |