
- 링크:
Background
- QA systems
- context retriever과 machine reader인 2단계로 구성되어 있음
- context retriever: answer이 담긴 passage를 선택
- machine reader: retrieved context를 조사하고 정답 식별
- passage를 가져오는 retriever의 성능이 중요
- Retriever1 - Traditional sparse vector space model
- open-domain question answering task는 후보 context 중에 efficient passage를 잘 선택하는 것이 중요
- TF-IDF
- t: 용어 (단어), d: 문서 (문장들)
- tf(t, d): 한 문서 내에 같은 단어가 여러 번 등장하면 증가
- idf(t, D): 여러 문서에서 같은 단어가 등장하면 감소
- tfidf(t, d, D): tf(t,d)xidf(t,D)
- -> 적은 문서에서 많이 등장 하는 것이 목적에 맞는 전문 용어이니 통계를 기반으로 문서 선택
- -> 하지만 문서가 길수록 유리해 잘못 선택될 수 있음
- BM25
- TF-IDF의 개선 버전
- 보정 파라미터를 추가하여 TF의 영향을 줄이고, IDF의 영향을 키움
- 문서 길이의 영향을 줄임
- -> sparse vector space model이 아닌 dense representations의 dual-encoder framework를 사용하면 어떨까?
- Retriever2 - ICT (Inverse-Cloze-Task)
- 가려진 부분의 텍스트를 이용해 그 주변의 텍스트들을 예측해내는 것.
- 문서들 Z 중 임의의 문서 90%의 문서 z에서 문장 x를 지우고 x가 있던 문서 z'를 찾도록 학습함
- 하지만 3가지 한계점이 있었음
- ICT pretraining은 computationally intensive함 (적은 학습하는데 많은 자원이 듬)
- 질문 또는 일반 문장 (데이터 부족 등의 문제로)과 관련 문서를 찾도록 학습하는데 이게 적절할까?
- context encoder가 QA 데이터로 fine-tuning되지 않아 해당 표현이 최적이 아닐 수 있
- 그 외 몰랐던 용어
- cross-attention mechnism: transformer의 encoder 부분이 아닌 decoder 부분에서 input이 두개 들어가는 거
- knowledge-intensive task: 사람도 외부 지식 (웹 검색) 없이는 해결하기 어려운 task
- triplet loss: 기준 A를 Positive Sample과는 가깝게, Negative Sample과는 멀어지게 학습
- hard sample: 모델이 Positive인지 Negative인지 구분하기 어려워하는 데이터
- Non-iid: 분포가 불균형함
- MIPS (Maximum Inner Product Search): 쿼리 벡터와 문서 벡터의 내적 값이 가장 큰 것을 찾는 알고리즘
Methods
- 용어
- collection of Documents D: 문서들 {d1, d2, d3, ... dn}
- total corpus M: documents를 쪼갠 문장들 {p1, p2, p3, ... pn}
- token w|pi|(e): pi번째 passage의 e번째 토큰
- retriever R(q, C) -> Cf: C에서 question q와 관련된 passage k의 집합을 선택
- dense encoder Ep(.): text passage를 d-dimensional real-valued vectors로 변환하고, M에 대한 index를 만듬
- encoder EQ(.): input question을 d-dimensional vector로 변환하고 k개의 passage를 선택함
- Architecture
- passage encoder과 question encoder 둘 다 어떤 신경망이든 쓸 수 있지만 해당 논문에서는 standard BERT pretrained model을 사용
- dual-encoder architecture를 활용한 DPR 제안
- Inference: encoder Ep의 index로 FAISS 사용하여 vq = EQ(q)를 도출
- DPR (Dense Passage Retriever)
- passage를 sparce vector가 아닌 dense vector로 표현 == low-dimensional and continuous space에 투영
- Training
- 유사도를 구해서 관련된 문서를 뽑고자 함
- 이때 cross attentions 등을 사용하는 방법도 있는데 M의 embedding representation이 사전에 계산될 수 있도록 decomposable해야함
- ablation study에서 다른 유사도 함수들도 비슷한 성능을 내서 간단한 inner product를 선택

- Metric learning
- Metric learning: space 공간에 거리를 조절하도록 학습하는거라고만 이해함
- questions and passage pair가 가까운 거리에 매핑되도록 vector space를 학습
- 추가적인 학습 없이 Question-Passage 페어를 활용한 dense embedding model를 사용하고자 함
- positive sample은 가까워지고, negative sample은 멀어지도록 학습
- contrastive learning할 때 보통 positive sample 하나, negative sample을 여러개를 사용: 학습 방향성의 안정을 위해 loss를 줄이기 위해서는 긍정 예제랑 더 비슷해져야하는데 positive 예제를 많이 쓰면 앵커랑 여러 방향을 당겨져서
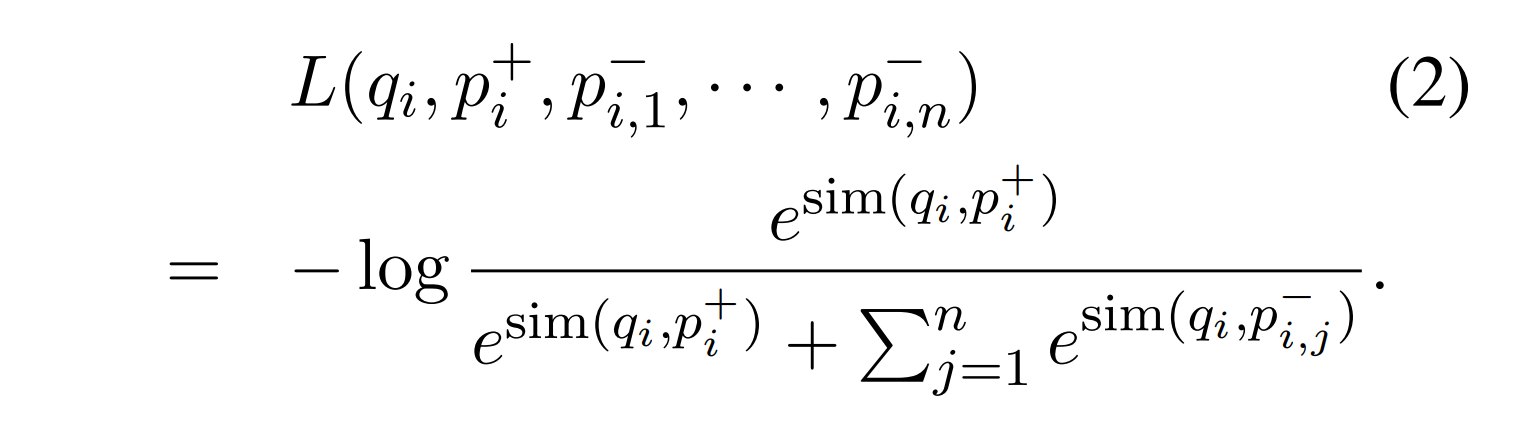
Experiment & Analysis
- Setting
- 40 epoch for large dataset, 100 epoch for small dataset
- learning rate of 10-5 using Adam
- linear scheduling with warm-up
- dropout rate 0.1
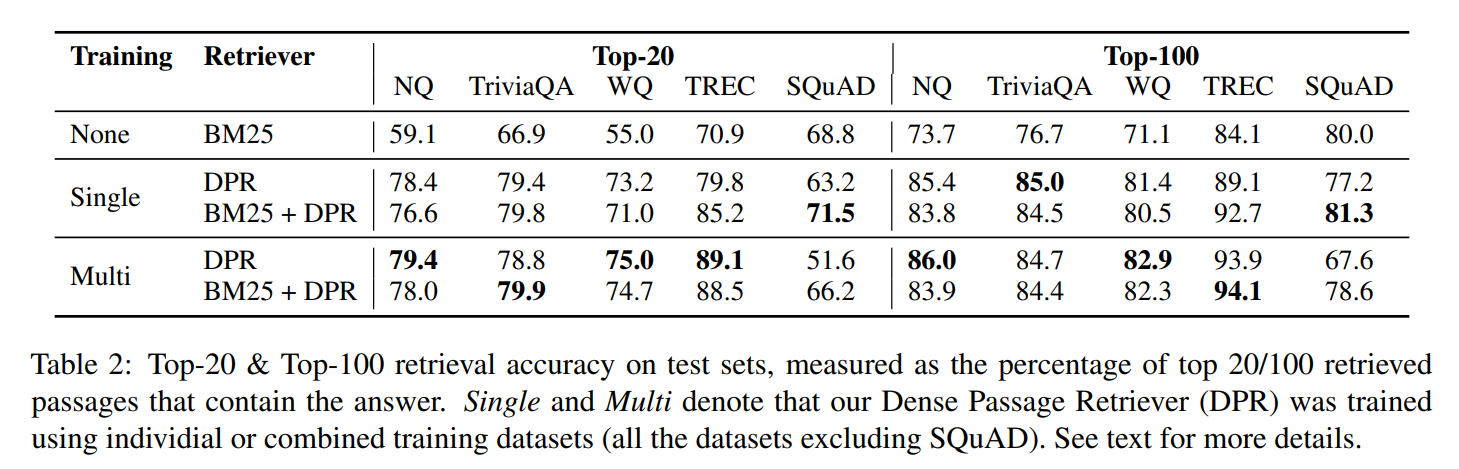
- Table 2
- SQuAD를 제외하고 DPR을 적용했을 때 더 높은 성능을 보임
- SQuAD의 성능이 낮은 이유는 2가지를 추측
- passage를 보고 question을 주석으로 달기 때문에 passage와 question 사이의 높은 overlap -> BM25 (통계 기반) 가 더 유리함
- data를 오직 wikipedia articles에서 수집했기 때문에 편향되었
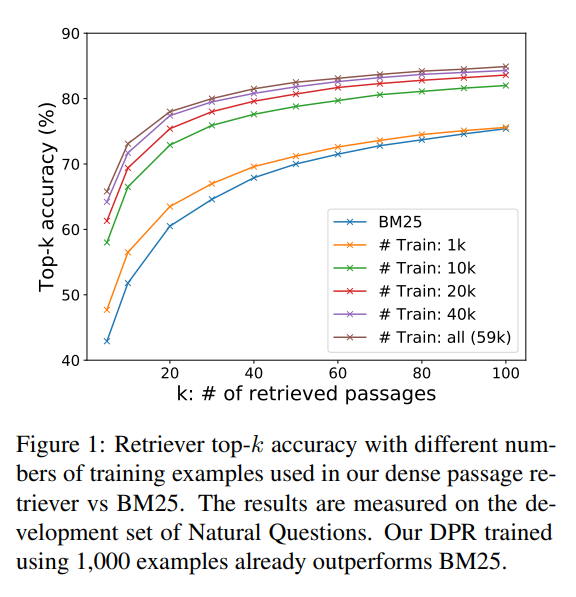
- Figure 1
- training example의 수를 늘릴수록 일관되게 성능이 향상함
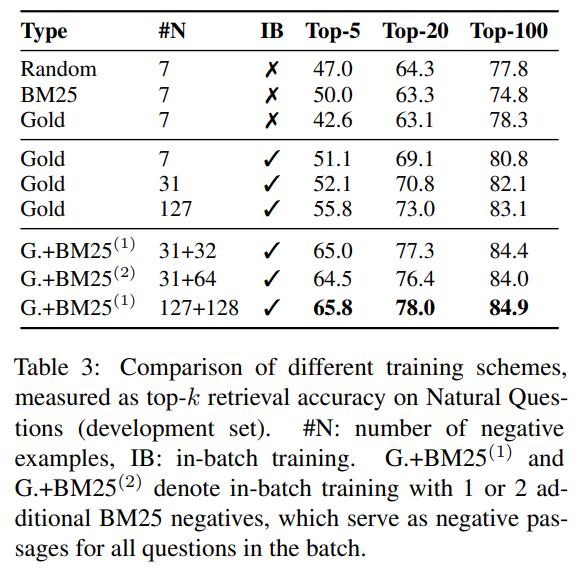
- Table 3
- Random: 무작위 문서로 학습
- BM25: 통계 기반 문서로 학습
- Gold: 해당 정답이 있는 문서와 gold negative를 사용한 문서로 학
- 수식 3, 4, 5
- (3) passage의 시작을 예측
- (4) passage의 끝을 예측
- (5) passage를 선택 (정답이 passage 하나에만 들어있는 경우)
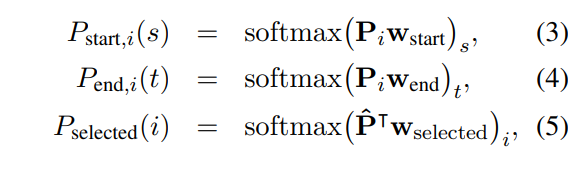
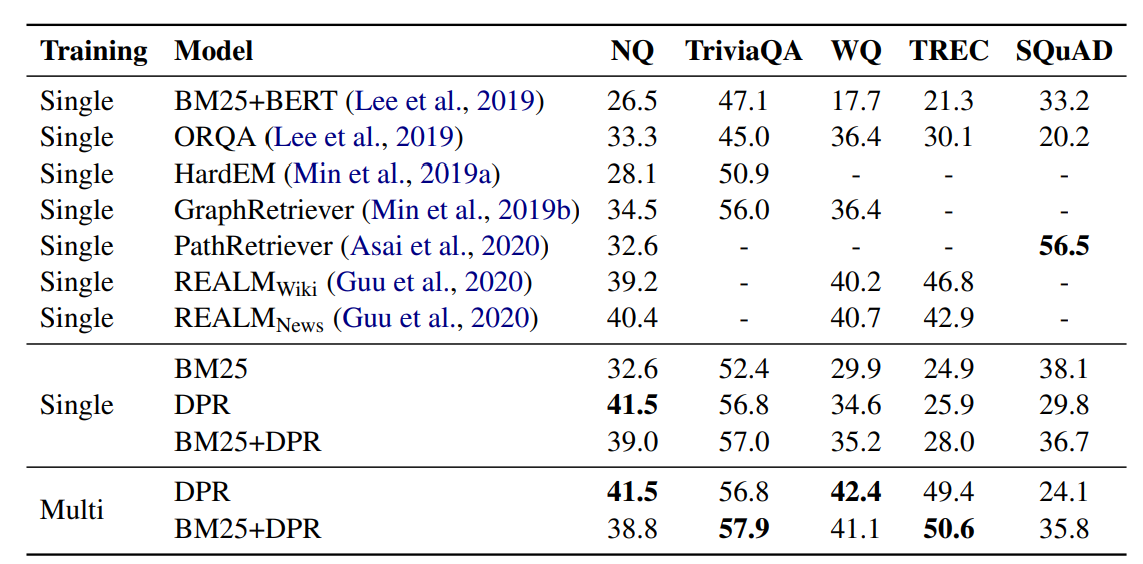
- Table 4
- Single: 하나의 데이터셋으로만 학습
- Multi: 여러 데이터셋으로 학습
- Multi training 학습은 모델의 범용성과 성능을 향상시킴
- DPR을 적용하면 높은 성능을 보임
Result & Contribution
- proper training (추가적인 학습 없이 encoder를 question-passage pairs로 학습)하여 BM25를 능가
- higher retrieval precision이 higher end-to-end QA accuracy로 이어짐을 증명
- 4/5 dataset에서 SOTA 달성
Limitation
- 기존 통계 기반 모델에 비해 많은 데이터와 컴퓨팅 자원이 필요 (BERT)
- 낮은 성능을 보이는 task도 있음
'논문 리뷰 > 자연어처리' 카테고리의 다른 글
| Training language models to follow instructions with human feedback 리뷰 (0) | 2025.05.26 |
|---|---|
| Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks 논문 리뷰 (1) | 2025.05.22 |
| FINETUNED LANGUAGE MODELS ARE ZERO-SHOTLEARNERS (0) | 2025.05.13 |
| Language Models are Few-Shot Learners 리뷰 (0) | 2025.05.12 |
| Language Models are Unsupervised Multitask Learners 리뷰 (0) | 2025.05.11 |