https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
Background
- Supervised learning
- 많은 양의 데이터를 pretrain하고 각 task별로 finetuning을 해야 높은 성능을 낼 수 있음
- multi-task tuning의 경우 각 task 별로 tuning한 것보다는 낮은 성능을 보여 각 task 별로 튜닝이 필요했음
Methods
- architecture
- GPT-1과 마찬가지로 Transformer의 decoder block을 쌓아 만듬
- layer normalization 추가
- residual layer의 가중치 설정
- vocab size와 context size 증가
- Pretraining
- 수식 1: 앞 n개의 토큰을 보고 다음 토큰을 예측하는 방법으로 pretraining
- 다양하고 많은 데이터로 학습 진행
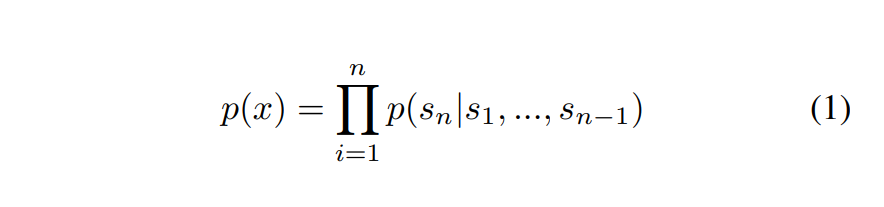
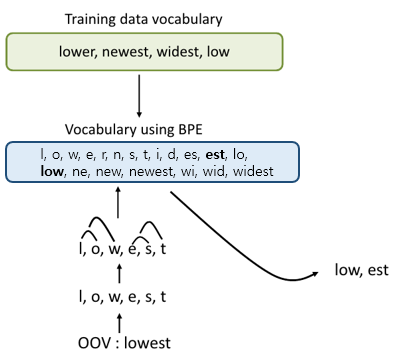
- BPE (Byte Pair Encoding)
- GPT-1의 경우 word를 기준으로 vocab을 만들었지만, gpt-2에서는 BPE를 활용해 효율적으로 충분한 의미를 표현할 수 있게됌
- Prompt 작성
- Translated to English: 라는 프롬프트를 작성해주는 것만으로 번역을 잘 함
- Multi-task learning without gradient updates가 가능해짐
- 프롬프트만 작성하여 별도의 학습 없이도 여러 작업 수행이 가능함 -> 이후 Prompting / In-Context Learning으로 이어짐
Experiment & Analysis
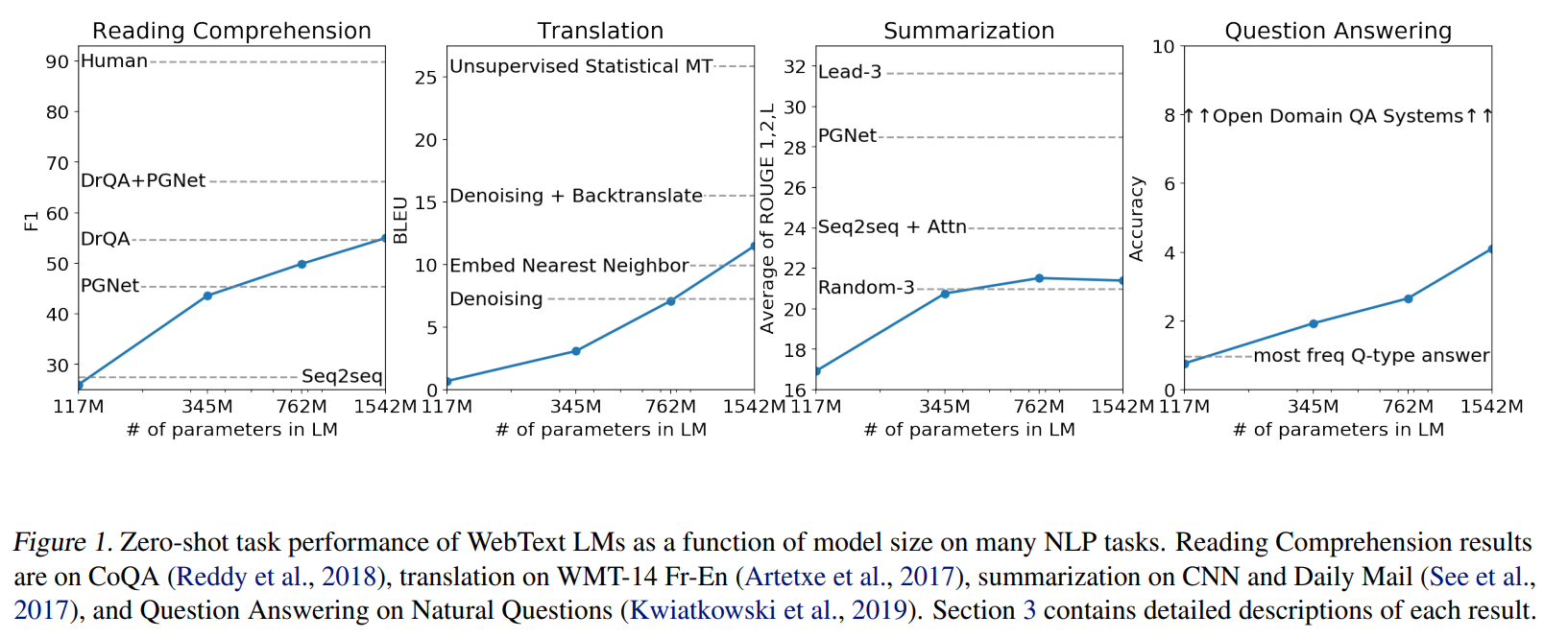
- Figure1
- 점선이 이전 SOTA, 실선이 zero-shot
- 이전 SOTA와 비슷한 성능을 내기도 하지만 아직 못 미치는 task도 있음
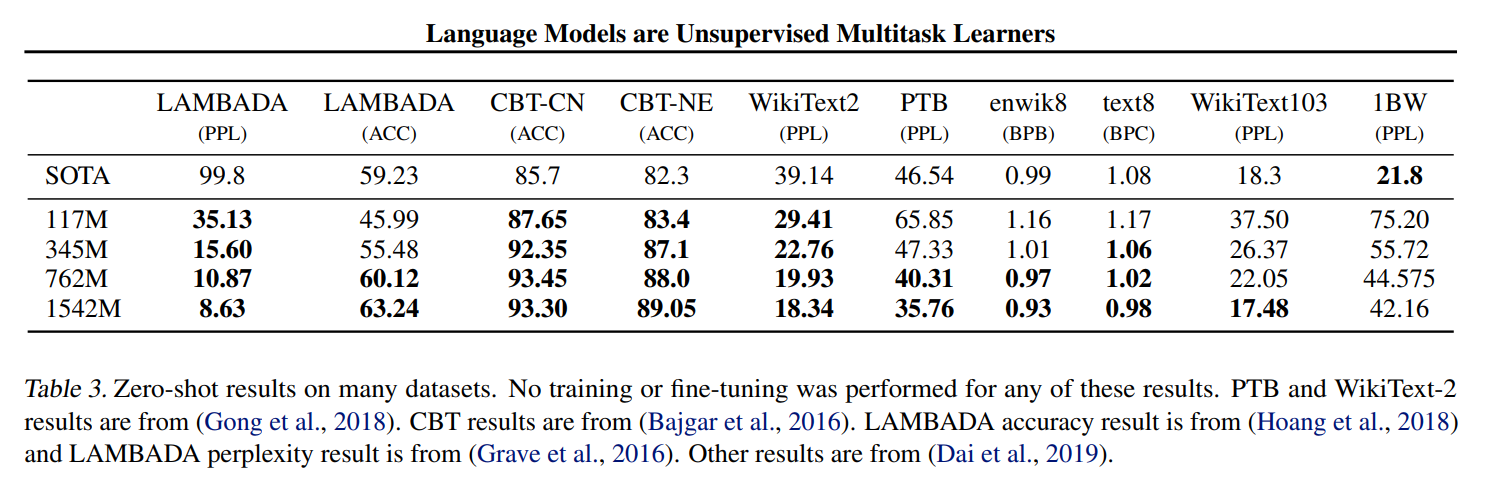
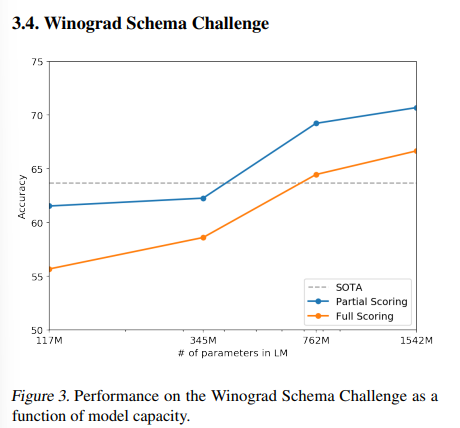
- Figure 3
- 파란선은 출력에 정답이 포함되기만 하면 됌
- 주황선은 class 별 probability를 구해 정답을 더 높게 예측해야 정답 -> 더 어려운 task
- zero-shot이 모델의 크기가 커질 수록 높은 성능을 보임을 증명
- 많은 실험에서 모델이 클 수록 높은 성능을 보이는 것을 확인 -> 이후 Scaling Law, Chinchila 등의 후속 연
- Figure 4
- rouge-n으로 성능을 평가
- GPT-2 TL; DR: 이라는 프롬프트로 요약을 유도
- 그 외에는 비교 모델들
- GPT-2 no hint와 비교해 성능 차이가 많이 남 -> 이후 Few-shot 및 Instruction tuning

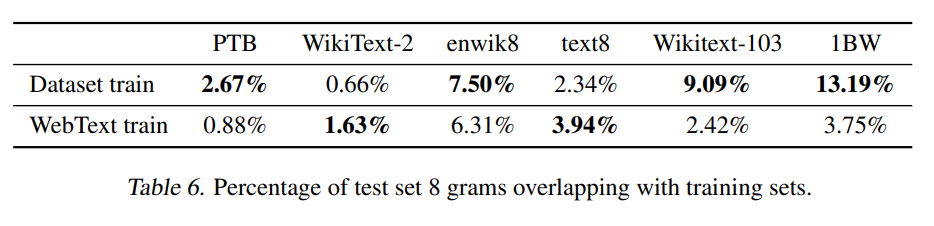
- Table 6
- train data와 test data의 8 gram overlapping (8 단어 연속으로 겹치는지)를 측정해 test data가 얼마나 독립되어 있는지 확인
Result
- zero-shot setting에서 7/8 dataset에서 SOTA
- 고품질의 WebText dataset 생성
Limitation
- 학습시키려면 많은 컴퓨팅 자원 필요
- Finetuning에 비해서는 낮은 성
