
- 링크:
https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
Background
- Tuning
- 모델을 scratch부터 labeled data로 학습시키는 것은 많은 데이터가 필요한데 데이터를 만드는데 많은 비용가 시간이 듬
- 모델이 labeled data에 과적합되거나 편향될 수 있음
- Pretrained word embedding
- 사전에 학습된 단어 임베딩을 사용하는 이전 연구가 있음
- 이 연구에서는 unlabeled text에서 word-level 정보를 활용함
- Leveraging unlabeled text
- unlabeled text에서 단어 수준 이상의 정보를 활용하는 것은 어려움
- 어떤 유형의 optimization objectives가 효율적인지 알기 어려움 -> 여러 연구에서 각 방법이 다른 작업에서 우수한 성능을 보임
- trained representation을 task로 옮기는 방법에 대해 합의가 안됌
- 모델을 각 task별로 사용하거나, 복잡한 학습 방법을 사용하거나, 보조 학습 목표를 추가하는 방법이 있었음
- Language processing을 위한 semi-supervised learning이 어려웠음
-> language understanding tasks를 위한 semi-supervised 방법을 제안
- Related Work
- Semi-supervised learning for NLP: word-level, phrase-level, sentence-level 등 다양한 방식으로 학습 -> 우리는 word-level
- Unsupervised pre-training: linguistic information을 학습하기 위해서 LSTM을 사용 -> 우리는 Transformer
- Auxiliary training objectives: semi-supervised learning 대신 사용 -> 우리도 auxiliary objective를 사용하지만 unsupervised pre-training에서 이미 학습됨
Methods
- Framework
- Generative pre-training과 discriminative fine-tuning 두 단계로 진행
- Transformer 모델의 decoder block만 사용
- pretraining된 모델에 task에 맞는 레이어 (Text Prediction, Task Classifier) 를 추가
- 모든 task에서 start token <s>와 end token <e>를 사용함
- 하이퍼파라미터: 768 dimensional states, 12 attention heads, 3072 dimensional position-wise feed-forward networks, BPE vocab

- Unsupervised pre-training
- unlabeled data의 다음 단어를 예측하는 방식으로 사전 학습
- downstream task 와 다른 domain의 데이터로도 pretraining할 수 있음
- 수식 (1): 모델 파라미터가 Θ일때, 앞의 k개의 토큰을 바탕으로 현재 토큰 ui의 확률을 예측해 최대가 되도록 함
- 수식 (2)-1: 입력 토큰 시퀀스 U와 word embedding We를 곱하고, position embedding Wp를 더해 초기값 설정
- 수식 (2)-2: transformer block에 넣어 나온 값을 다음 hidden state에 저장
- 수식 (2)-3: 최종 hidden state에 word embedding WeT를 곱하고 Softmax를 취해 모든 단어에 대한 확률 분포 출력

- Supervised fine-tuning
- Task에 따라 다른 adaptation layer를 추가
- Labeled data로 adaptation 부분을 Finetuning
- 수식 (3): transformer decoder block의 마지막 토큰의 hidden state에 softmax를 씌워 클래스 별 확률을 계산해 라벨 y를 예측
- 수식 (4): 전체 데이터셋 C에 대해 로그 확률을 최대화
- 수식 (5): L1은 pretraining loss (language modeling), L2 finetuning loss (cross-entropy)의 가중치를 조절

Experiment & Analysis
- NLU task 4가지에 대해 평가: NLI, QA, semantic similarity, text classification
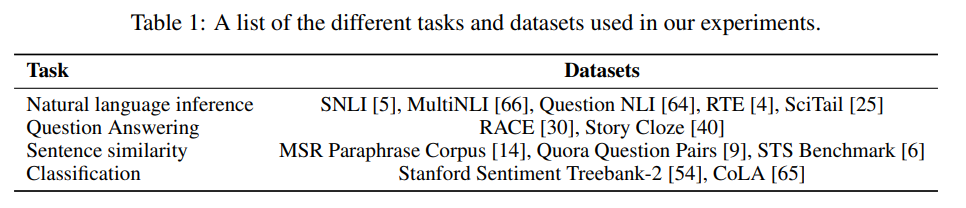
- 다양한 task에서 SOTA 달성



- Figure 2-1
- of layers transferred: pretraining한 block을 finetuning한 레이어의 수
- 많은 층을 finetuning할 수록 높은 성능을 보임

- Figure 2
- zero-shot (pretraining 후 finetuning하지 않음) 성능에서도 당시 성능과 비교해 SOTA 달성했음
- 이를 통해 language modeling과 attentional memory의 효과를 알 수 있음

- Table 5
- ablation study 진행
- auxiliary objective는 큰 데이터셋에서만 성능 개선을 보임
- LSTM을 사용했을 때 성능이 감소함
- pretraining 없이 바로 supervised target tasks에 대해 학습했을때 크게 성능이 감소

Result
- 9/12 task에서 SOTA
- Transformer architecture를 기반으로 pretraining의 중요성을 증명
Limitation
- Task 별 Fine-tuning 필요
- Decoder-only 구조라 bidirectional context 학습 불가
- Pretraining 시간과 비용이 많이 듬
'논문 리뷰 > 자연어처리' 카테고리의 다른 글
| Language Models are Few-Shot Learners 리뷰 (0) | 2025.05.12 |
|---|---|
| Language Models are Unsupervised Multitask Learners 리뷰 (0) | 2025.05.11 |
| P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks 리뷰 (1) | 2025.05.09 |
| P-Tuning 1: GPT Understands, Too (1) | 2025.05.07 |
| Prefix-Tuning: Optimizing Continuous Prompts for Generation (0) | 2025.05.02 |
- 링크:
https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
Background
- Tuning
- 모델을 scratch부터 labeled data로 학습시키는 것은 많은 데이터가 필요한데 데이터를 만드는데 많은 비용가 시간이 듬
- 모델이 labeled data에 과적합되거나 편향될 수 있음
- Pretrained word embedding
- 사전에 학습된 단어 임베딩을 사용하는 이전 연구가 있음
- 이 연구에서는 unlabeled text에서 word-level 정보를 활용함
- Leveraging unlabeled text
- unlabeled text에서 단어 수준 이상의 정보를 활용하는 것은 어려움
- 어떤 유형의 optimization objectives가 효율적인지 알기 어려움 -> 여러 연구에서 각 방법이 다른 작업에서 우수한 성능을 보임
- trained representation을 task로 옮기는 방법에 대해 합의가 안됌
- 모델을 각 task별로 사용하거나, 복잡한 학습 방법을 사용하거나, 보조 학습 목표를 추가하는 방법이 있었음
- Language processing을 위한 semi-supervised learning이 어려웠음
-> language understanding tasks를 위한 semi-supervised 방법을 제안
- Related Work
- Semi-supervised learning for NLP: word-level, phrase-level, sentence-level 등 다양한 방식으로 학습 -> 우리는 word-level
- Unsupervised pre-training: linguistic information을 학습하기 위해서 LSTM을 사용 -> 우리는 Transformer
- Auxiliary training objectives: semi-supervised learning 대신 사용 -> 우리도 auxiliary objective를 사용하지만 unsupervised pre-training에서 이미 학습됨
Methods
- Framework
- Generative pre-training과 discriminative fine-tuning 두 단계로 진행
- Transformer 모델의 decoder block만 사용
- pretraining된 모델에 task에 맞는 레이어 (Text Prediction, Task Classifier) 를 추가
- 모든 task에서 start token <s>와 end token <e>를 사용함
- 하이퍼파라미터: 768 dimensional states, 12 attention heads, 3072 dimensional position-wise feed-forward networks, BPE vocab
- Unsupervised pre-training
- unlabeled data의 다음 단어를 예측하는 방식으로 사전 학습
- downstream task 와 다른 domain의 데이터로도 pretraining할 수 있음
- 수식 (1): 모델 파라미터가 Θ일때, 앞의 k개의 토큰을 바탕으로 현재 토큰 ui의 확률을 예측해 최대가 되도록 함
- 수식 (2)-1: 입력 토큰 시퀀스 U와 word embedding We를 곱하고, position embedding Wp를 더해 초기값 설정
- 수식 (2)-2: transformer block에 넣어 나온 값을 다음 hidden state에 저장
- 수식 (2)-3: 최종 hidden state에 word embedding WeT를 곱하고 Softmax를 취해 모든 단어에 대한 확률 분포 출력
- Supervised fine-tuning
- Task에 따라 다른 adaptation layer를 추가
- Labeled data로 adaptation 부분을 Finetuning
- 수식 (3): transformer decoder block의 마지막 토큰의 hidden state에 softmax를 씌워 클래스 별 확률을 계산해 라벨 y를 예측
- 수식 (4): 전체 데이터셋 C에 대해 로그 확률을 최대화
- 수식 (5): L1은 pretraining loss (language modeling), L2 finetuning loss (cross-entropy)의 가중치를 조절
Experiment & Analysis
- NLU task 4가지에 대해 평가: NLI, QA, semantic similarity, text classification
- 다양한 task에서 SOTA 달성
- Figure 2-1
- of layers transferred: pretraining한 block을 finetuning한 레이어의 수
- 많은 층을 finetuning할 수록 높은 성능을 보임
- Figure 2
- zero-shot (pretraining 후 finetuning하지 않음) 성능에서도 당시 성능과 비교해 SOTA 달성했음
- 이를 통해 language modeling과 attentional memory의 효과를 알 수 있음
- Table 5
- ablation study 진행
- auxiliary objective는 큰 데이터셋에서만 성능 개선을 보임
- LSTM을 사용했을 때 성능이 감소함
- pretraining 없이 바로 supervised target tasks에 대해 학습했을때 크게 성능이 감소
Result
- 9/12 task에서 SOTA
- Transformer architecture를 기반으로 pretraining의 중요성을 증명
Limitation
- Task 별 Fine-tuning 필요
- Decoder-only 구조라 bidirectional context 학습 불가
- Pretraining 시간과 비용이 많이 듬