논문 리뷰/자연어처리
Self-supervised Preference Optimization: Enhance Your Language Model with Preference Degree Awareness 리뷰
kyj0015
2025. 6. 11. 22:49
- 링크:
https://aclanthology.org/2024.findings-emnlp.845.pdf
Background
- RLHF
- https://kyj0105.tistory.com/98
- 기존의 연구들은 대부분 supervised fine-tuning과 preference optimization 두 단계로 이루어져 있음
- 그 중 DPO의 경우 선호되는 답변을 생성하고, 비선호되는 답변은 생성하지 않도록 바로 학습
- RM 없이 사람의 선호도를 학습시킨 첫 연구 -> reward model의 중요한 측면을 간과함
- 대부분의 RLHF 연구는 binary cross-entropy로 선호/비선호로만 학습하는 과정에서 다양한 선호 정보를 잃어버림
- -> RM 없이 다양한 사람의 선호 정보를 LM에게 학습시켜보자

Methods
- SPO
- self-supervised preference degree loss과 alignment loss를 결합하여 사용하여 LLM이 degree of preference를 이해하도록 함
- degree of human preference를 배우는 동시에 LLM과 human preference가 align하게 만듬
- Framework
- 선택적으로 선호 정도를 달리하는 응답에서 key를 제거하는 self-supervised task
- 학습동안 keyward extractor로 key content를 추출함
- 다른 양의 content를 제거함으로써 다른 정도의 선호 응답을 생성할 수 있으며 하나의 LLM output에 대해 여러 응답 생성 가능
- 이 key content를 포함한 LLM의 대답이 preference information과 면밀한 관계가 있음을 관찰함

- Self-supervised Preference Optimization
- 기존에는 LLM으로 여러 답변을 생성하고 해당 답변에 수동으로 annotate 또는 rank해서 preference level을 학습시켰음 -> 많은 시간과 자원이 듬
- 우리는 preference data에서 key content를 추출하고 제거함으로써 human preference level을 구별
- key content와 preference information이 밀접한 관계가 있음이 드러남
- 특히 학습 중 LLM이 예측한 모든 토큰을 해당 텍스트로 decoding한 후, RAKE를 용해 text의 key content를 찾아냄
- 이 때 keyword는 common stop words와 punctuation을 제외한 구문이라는 전제하에 작동 -> 후보 k에 대해 점수 계산
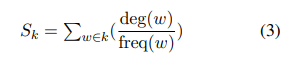
- 제거한 keyward 개수에 따라 라벨을 부여하여 N개의 카테고리로 분류
- 그리고 각 데이터의 카테고리를 self-supervised로 학습
- hidden state에 positional encoding을 추가
- loss-pref와 loss-dispref를 함께 사용
Contribution
- 기존의 direct human preference alignment methods (binary training mechanism)은 LLM이 사람의 선호 정도를 구별하지 못하도록 제한함을 최초로 발견
- self-supervised preference optimization framework를 제안하여 annotation이나 inference costs를 늘리지 않 human preference alignment를 강화함
- 실험을 통해 LLM이 선호도 구분 능력을 향상시키면 성능을 개선할 수 있음을 증명하며, 2가지 task에서 SOTA 달성
Experiment
- 2 dataset (Antropic HH, TL;DR summarization) 에 대해 실험하여 SPO를 증명
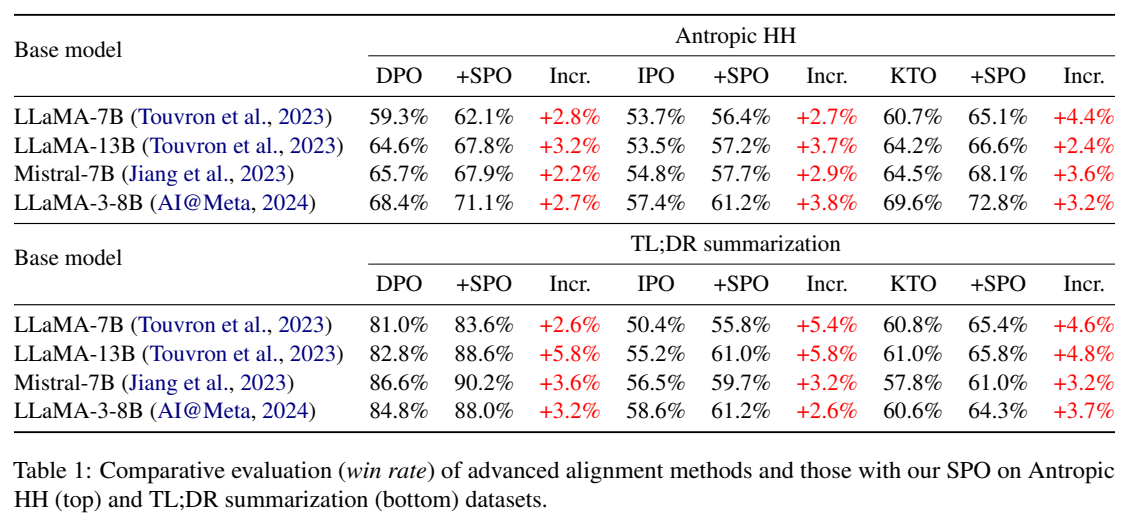
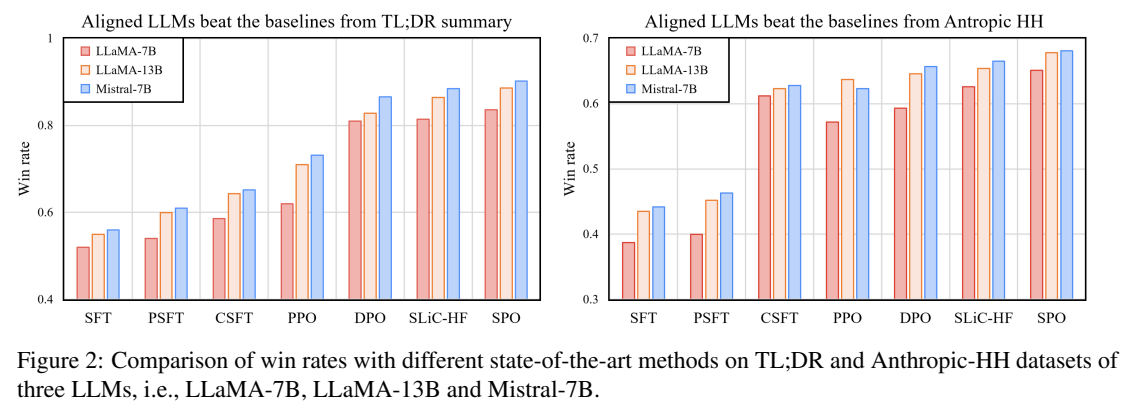
- Table 1, Figure 2, Table 2, Table 4
- SPO를 적용하니 일관되게 성능이 향상함
- pref 모듈과 dispref 모듈을 개별로 사용해도 성능이 증가하고, 두개를 동시에 사용하면 가장 높은 성능을 낼 수 있음


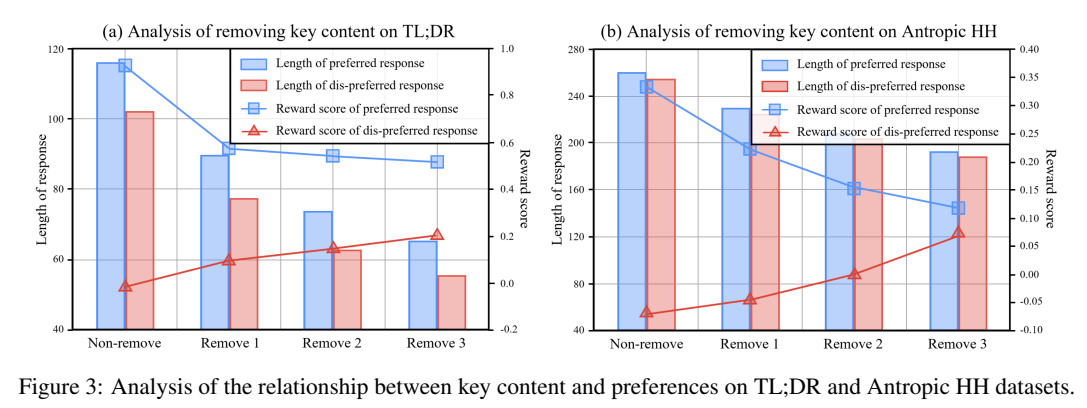
- Figure 3
- Key content가 줄어들수록 응답의 길이가 일관되게 감소함
- 선호도가 감소하고, 비선호도가 증가하는 것을 보아 key content가 빠지면 모델은 비선호되는 응답을 생성함을 알 수 있음
- Table 3
- random reval vs removal of key content: key content 추출 방식이 더 효과적

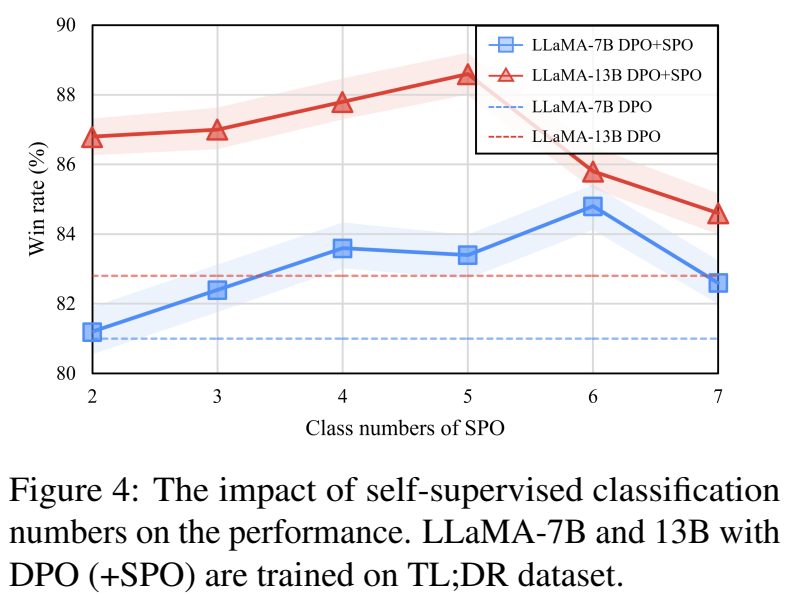
- Figure 4
- self-supervised method를 추가하니 성능 향상
- class number가 너무 크면 성능 감소가 있음
- Table 5
- keyward extracting 방식 중 RAKE가 가장 높은 방식을 보임

- Figure 5
- 가중치 r에 대한 비교 실험을 통해 최적의 값을 찾음

- Figure 6
- 1000 step만에 빠르게 높은 성능에 달성함

Result
- 기존 연구에 비해 다양한 선호도를 반영하도록 학습
Limitation
- 여전히 human preference data가 필요
- 거대 모델이 필요