
기본 미션
k-평균 알고리즘 작동 방식 설명하기
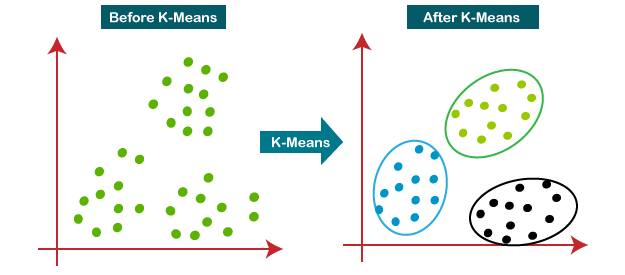
앞에서 배운 군집 알고리즘은 각 클래스의 이미지의 평균값을 구해서 그 평균값과 가까운, 비슷한 이미지를 찾아주는 방식이다. 하지만 클래스의 갯수나 종류를 알 수 없을때에는 어떡할까? 픽셀간의 차이의 절대값의 합을 이용해서 적절한 k값(클래스의 개수)을 찾아서 비슷한 이미지끼리 묶어주는 것이었다. 이 때 처음에 랜덤하게 정하는 클러스터의 중심이 k-평균이고, k-평균 알고리즘이 만든 클러스터에 속한 샘플의 특성 평균값이 센트로이드(클러스터 중심)이다. 그리고 k값을 구하는 방법이 엘보우 방법이고, 이너셔는 클러스터 중심과 샘플 사이 거리의 제곱 합이다.
선택 미션
Ch.06(06-3) 확인 문제 풀고, 풀이 과정 정리하기
1. 2
2. 2
3. 1
개념 정리
클러스터: 클러스터링(군집화)으로 만들어진 셋
클러스터 중심(센트로이드): k-평균 알고리즘이 만든 클러스터에 속한 샘플의 턱성 평균값
엘보우 방법: 최적의 클러스터 개수를 정하는 방법 중 하나. 이너셔(클러스터 중심과 샘플 사이 거리의 제곱 합) 감소가 꺽이는 부분이 적절한 클러스터 개수 k
주성분 분석: 차원 축소 알고리즘 중 하나로 데이터에서 가장 분산이 큰 방향을 찾는 방법. 이때 가장 분산이 큰 방향을 주성분이라 한다. 설명된 분산은 부성분 분석에서 주성분이 얼마나 원본 데이터의 분산을 잘 나타내는지 기록한 것.
메모
'혼공단' 카테고리의 다른 글
| [혼공단 11기] 혼공머신 7주차 (1) | 2024.02.25 |
|---|---|
| [혼공단 11기] 혼공머신 6주차 (0) | 2024.02.17 |
| [혼공단 11기] 혼공머신 4주차 (0) | 2024.01.30 |
| [혼공단 11기] 혼공머신 3주차 (0) | 2024.01.18 |
| [혼공단 11기] 혼공머신 2주차 (0) | 2024.01.17 |