- 링크:
https://arxiv.org/pdf/2103.00020
Background
- Traditional vision model
- ResNet: CNN과 잔차학습으로 이미지의 클래스 예측
- ViT: 이미지를 패치로 쪼개서 넣어주는데, 첫번째 토큰이 [CLS] 토큰 기능을 해서 이미지의 class를 분류
- 전통적인 vision model은 1) 사람의 라벨링 필요 2) 고정된 라벨에 대해 학습함으로써 task 변경시 재학습 필요 3) 제로샷 전이 불가능
- Natural languge model
- GPT-3: 해당 모델은 통해서 모델의 사이즈와 데이터의 양을 키우면 zero-shot만으로도 높은 성능을 낼 수 있음을 보여줌
- 이를 통해 저품질의 대규모 웹 데이터를 활용하면 자연어처리 분야에서 큰 발전을 이룰 수 있음을 보여줌
- Multi-modal model
- Learning visual feature form large weakly supervised data: 웹 이미지에 달린 캡션의 단어의 집합을 예측하는 방법으로 이미지의 정보를 학습
- VirTex: 이미지의 캡션을 transformer decoder를 2개 사용해 예측
- 두 연구 모두 캡션을 잘 예측하는 것이 목적이 아닌 transferable visual representations를 학습하는 것이 목표였음
- 하지만 여전히 task가 바뀌면 추가적인 training이 필요하다는 단점이 있었음
- 어떻게 하면 자연어처리 분야가 아닌 비전 분야에서, 대규모 웹-이미지 데이터를 활용한, 확장 가능한 pretraining metohds로 gpt-3와 같은 성공을 거둘 수 있을까?
Methods
- 이론
- pair인 이미지는 가깝게, pair가 아닌 이미지는 멀게
- 그러면 같은 강아지 이미지인데 pair가 아니니까 이상하게 학습되는거 아니냐? -> 자연어처리 분야에서도 causal language modeling 방식으로 사람이 보기에 잘못된 loss가 예측될 수도 있으나 사람이 일일이 라벨링 하기 어려우니 대신하는 방법으로, 사람의 노동을 줄이기 위한 방법이니 어쩔 수 없고 상당히 효과적이다
- 데이터 전처리
- 이미지는 224x224로 random crop
- 텍스트는 앞에 [SOS], 뒤에 [EOS], 76 토큰 이상이면 자르기, 모두 소문자로 변경
- Contrastive pretraining
- Text encoder: 마지막 hidden state의 [EOS] 토큰 임베딩을 사용
- Image encoder: 마지막 hidden state의 임베딩 (차원 안 맞으면 projection layer)
- Pair인 임베딩 벡터 간의 consine similarity를 구해서, pair는 최대가 되게, pair가 아니면 최소가 되게
- Use for zero-shot prediction
- Class 명을 "A photo of a {object}."라는 고정된 프롬프트에 넣어 text encoder로 임베딩 벡터를 생성함
- Image encoder에 이미지를 넣어서 생성한 임베딩 벡터와 클래스 갯수만큼의 텍스트 임베딩 벡터 간에 유사도를 구해서 가장 유사도가 높은 클래스를 정답으로 예측
- 질문
- BERT 같은 모델은 [SOS] 토큰을 쓰는데 왜 [EOS] 토큰을 썼는지? -> 원래 autoregressive mask 방식을 사용하려해서
- Cosine similarity를 구하는데 왜 np.dot을 하는지? -> L2_normalize를 통해 같아짐
- Zero-shot, few-shot, linear probe clip이 각각 무슨 차이인지? -> zero-shot은 논문 그림에 있는거 그대로, linear probe clip은 이미지 인코더가 생성한 임베딩 벡터를 logistic regression layer로 다시 학습한 모델, 이 때 데이터를 몇개만 쓰면 few-shot clip
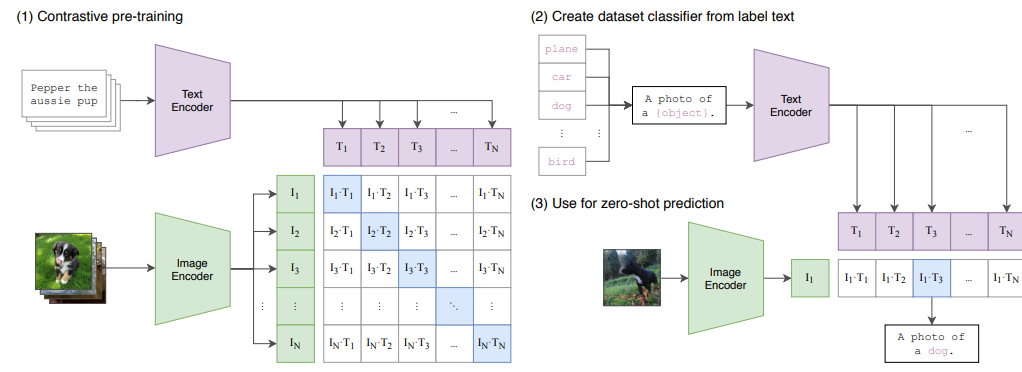

Experiment & Analysis
- Figure 2
- 앞선 연구들과 비교했을 때 이미지 인코더는 그대로 사용하고, 텍스트 인코더는 BoW 형식으로 예측하여서, 대조학습으로 학습하는게 가장 효율적이었음
- GPT-3처럼 성공하려면 모델 사이즈와 데이터양을 매우 키워야하기 때문에 가장 효율적인 방식을 사용해야했음

- Figure 4
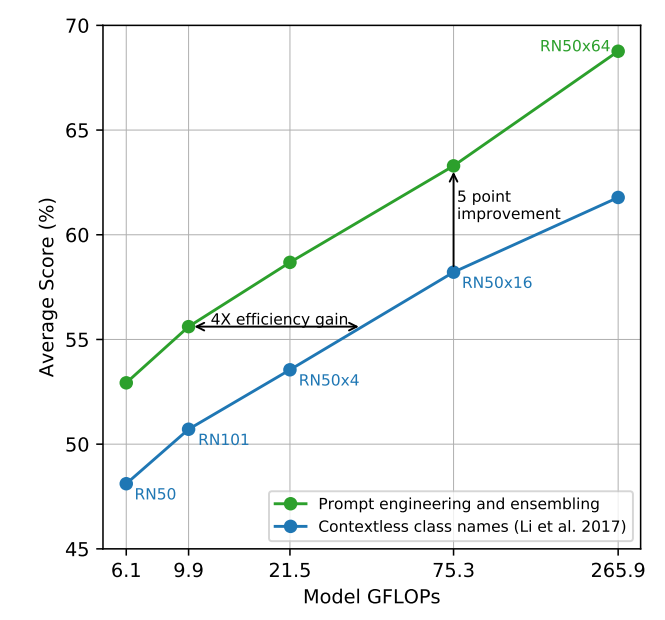
- Prompt를 "A photo of a {object}."만 사용하는거보다 각 task 맞는 프롬프트를 앙상블해서 사용하니 더 효율적이고 높은 성능을 달성했음
- Figure 5
- Zero-shot CLIP은 웹 이미지-텍스트 데이터를 바탕으로 학습했기 때문에 데이터의 분포가 비슷한 데이터셋의 task일수록 높은 성능을 달성함
- 분포가 다른 (사람에게도 어려운) task에서는 full finetuning보다 낮은 성능을 달성

- Figure 6
- Few-shot CLIP의 데이터 수에 따른 성능 비교
- Few-shot이라 해도 다른 방법론 보다는 높은 성능을 달성함
- 왜 Zero-shot이 few-shot보다 성능이 높지? -> 일반적으로 생각하는 GPT-3의 few-shot이 아니라 고정된 임베딩 벡터를 다시 학습하는 방법이라 데이터의 수가 적을 때는 zero-shot보다 낮은 성능을 달성함

- Figure 9
- 모델을 키울수록 연산량은 늘어나나 높은 성능을 달성함
- GPT-3처럼 모델의 사이즈를 키울수록 좋은게 multi-modal 분야에도 적용됨을 증명
- 이 때 transformer 모델 사이즈에는 큰 영향을 받지 않았고, image encoder의 사이즈가 영향을 미쳤다고 함

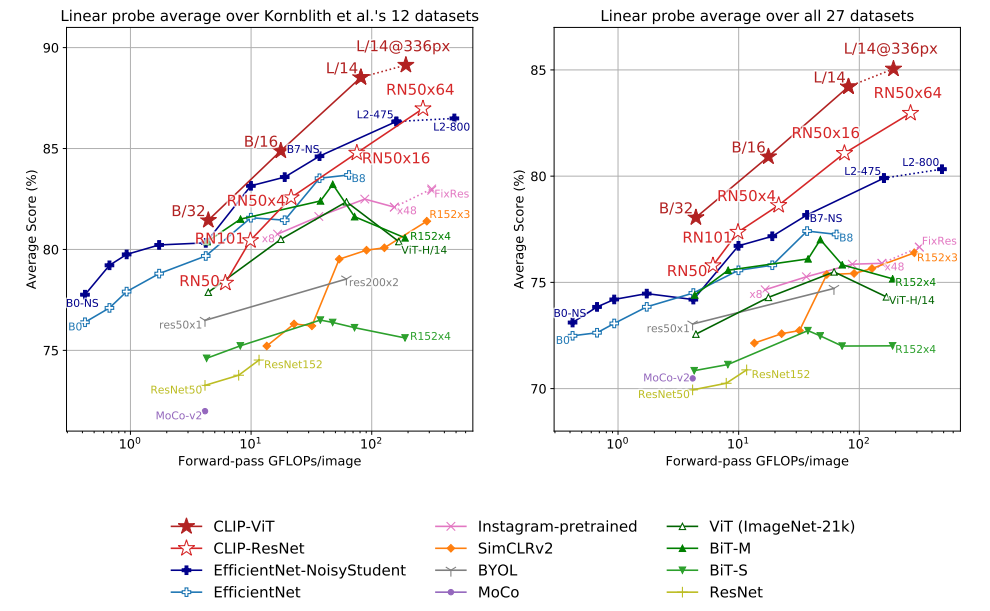
- Figure 10
- 비교 실험을 했을 때 CLIP이 가장 높은 성능을 달성함
- CLIP 논문은 zero-shot clip을 제안하기는 하였으나, 기존 SOTA 모델들은 full-finetuning으로 성능을 보고 했기 때문에 같은 환경에서 비교하기 위해서 논문의 저자들도 linear probe clip으로 비교
- 왼쪽 12-datset은 기존 SOTA 모델들과 그렇게 큰 차이가 안 나나, 오른쪽 27-dataset은 큰 차이가 남
- CLIP이 더 다양한 task에서 강건한 성능을 달성함을 보여줌
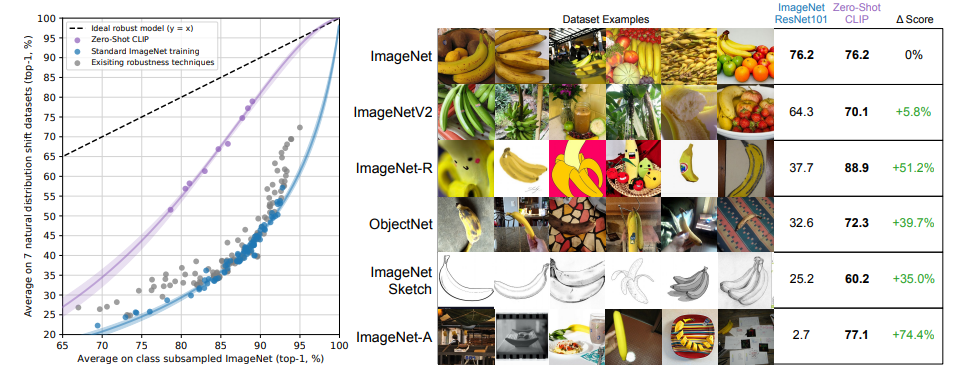
- Figure 13
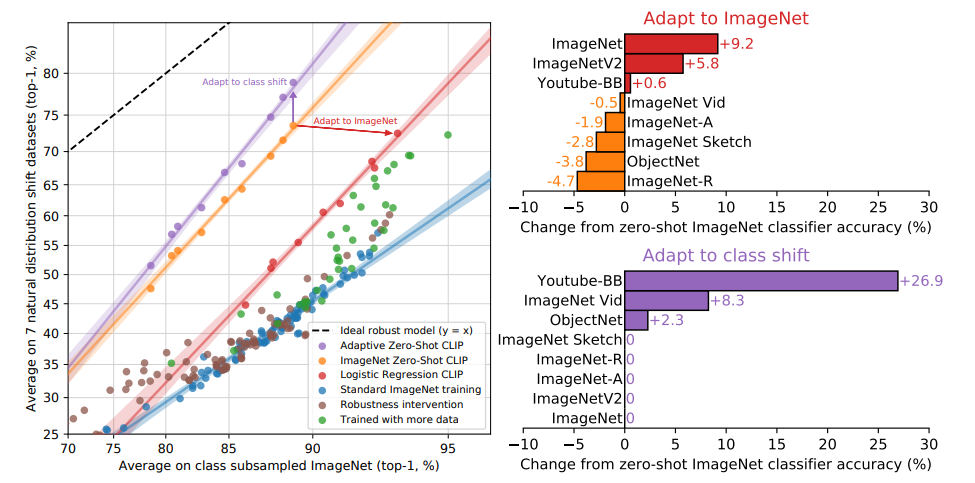
- Figure 10은 데이터셋의 변화에도 강건함을 증명했다면 Figure 13은 데이터의 natural distribution shift에도 강건함을 증명
- 대규모 데이터셋인 ImageNet에 finetuning한 모델은 ImageNet과 ImageNetV2에서만 높은 성능을 보이고 나머지는 매우 낮은 성능을 보임
- 하지만 zero-shot clip의 경우 다양한 task에서 일관되게 높은 성능을 달성함
- Figure 14
- 빨간색: ImageNet에서 tuning한 linear probe clip
- 주황색: ImageNet의 class의 명으로 작성한 프롬프트로 zero-shot clip
- 보라색: 논문의 저자가 제안하는 zero-shot clip (클래스의 분포가 변할 때 object만 바꿔껴주면 됨)
- Figure 15
- Zero-shot 뿐만 아니라 few-shot도 다른 모델에 비해 강건함을 보여줌

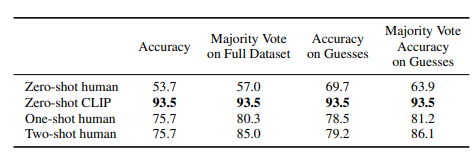
- Table 2
- 사람의 zero-shot 능력은 안 좋으나 one-shot만 주어져도 좋아짐 -> 사람은 무엇을 모르는지 모르는 상태
- 하지만 two-shot은 큰 차이 없음
- CLIP은 zero-shot 성능도 좋은데 데이터를 추가할 수록 일관되게 성능이 증가해 개선 여지가 있음
Result
- 대규모 웹-이미지 pair 데이터를와 간단한 대조학습을 활용한 CLIP 프레임워크 제안
- Distrubution shift에서 zero-shot learning도 강건함을 증명
- 27가지 dataset에서 추가적인 학습 없이도 강한 성능을 달성하며 CLIP의 가능성을 제안
Limitation
- Class prediction 과정에서 사람이 class를 지정해주어야함 -> 사람이 모르는 객체는 판별 불가