논문 리뷰/자연어처리
Training language models to follow instructions with human feedback 리뷰
kyj0015
2025. 5. 26. 00:51
- 링크:
https://arxiv.org/pdf/2203.02155
Background
- Reinforce learning
- Environment: state를 주는 상황 또는 환경 -> 입력 문장
- Action: state에 대한 agent의 행동 -> 출력 문장
- Agent: Policy에 따라 행동하는 모델 -> PPO 모델
- Critic: Actor의 행동을 평가하고 reward를 반환하는 모델
- Policy: Agent가 어떤 state에 놓였을 때 어떤 action을 할지 결정하는 strategy 또는 함수 -> PPO 모델 파라미터
- PPO
- RL 모델의 파라미터 업데이트 알고리즘
- PPO: KL divergence이 일정 이하가 되도록하거나 cliping으로 간단하게 발산하지 않게 조금씩 안정적인 학습
- Large Language model이 misaligned
- LLM 모델을 크게 만들고 학습시켜 prompted만으로 다양한 NLP task에서 성과를 보이나 꼭 사용자의 의도대로 대답을 생성하지는 않음 -> language modeling objective가 predicting the next token on webpage라서
- Untruthful, toxic, not helpful 등 -> 모델은 사용자의 의도와 aligned하지 못하다
- -> Reinforcement Learning from Human Feedback으로 align하게 finetuning하자
Methods
- 1. collect demonstration data, and train a supervised policy
- 40명의 labeller 고용
- 모델을 학습시킬 질문/답변 데이터셋 생성
- OpenAPI로 받은 prompt에 대해 모범적인 답변을 작성
- GPT-3를 위 데이터로 supervised learning -> SFT
- 2. Collect comparison data, and train a reward model
- SFT의 대답을 labeler의 선호대로 rating
- 이 데이터로 RM 모델을 학습
- 3. Optimize a policy against the reward model using reinforcement learning
- SFT로 모델 초기화
- RM의 reward가 최대가 되게 학습 (PPO 알고리즘)
- 1.3B InstructGPT가 175B GPT보다 align
- Model
- SFT (supervised fine-tuning): GPT-3 175B, finetuning 1 epoch 만으로 overfitting되서 RM score와 human preference ratins로 학습
- RM (reward modeling)
- prompt와 response를 받으면 scalar reward를 반환
- 6B
- loss가 작아지려면 log 값이 0에 수렴해야함 -> 두 답변에 대한 scalar reward (yw, yl)의 차이가 1에 가까워야함 -> 사람이 선호하는 답변 yw에 대해서는 1에 가까운 reward를 반환하고, 사람이 선호하지 않는 답변인 yl에 대해서는 0에 가까운 reward를 반환해야함
- K개의 데이터 중에서 2개를 뽑을 수 있는 경우의 수가 (K 2)
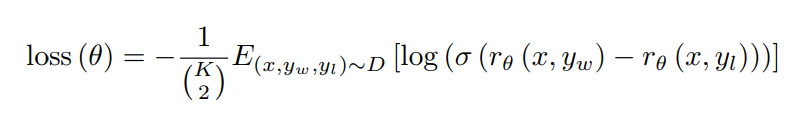
- Reinforcement learning (RL)
- PPO의 KL penalty를 사용함.
- policy의 분포 차이를 기반으로 업데이트에 제안을 두는 방법
- per-token KL penalty는 token을 기준으로 SFT와 분포가 너무 멀어지는 것을 방지
- rθ(x,y): 해당 문장이 사람이 선호하도록 커지게 학습
- -blog(): 업데이트 된 RL GPT가 예측한 토큰과 아직 업데이트 안 한 SFT GPT가 예측한 토큰의 차이가 적어지게 함
- +rlog(): pretrain data를 사용해 RL GPT이 크게 변하는 것을 방지
- 첫번째 수식이 PPO, 두번째 수식이 PPO-ptx
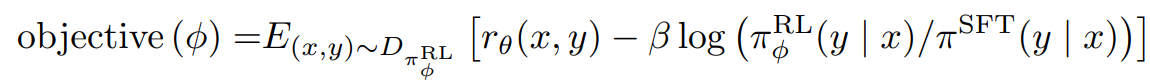

Experiment
- Dataset
- 1-1) 200 prompts per user ID를 train, val, test로 나누고 train만 개인식별정보 제거
- 1-2) labeler에게 prompt 작성 요청 -> plain, few-shot, user-based
- Plain: 여러 주제에 대해 다양하게 작성
- Few-shot: instruction + samples
- User-based: OpenAI 사용자들의 프롬프트 참고
- 애매한 경우 chat room으로 연구진이 판정 -> 연구진의 편향 반영이 가능하지만 labeler간의 일치율이 상당히 높음
- -> GPT-3 supervised finetuning dataset (13k)
- 2-1) SFT가 생성한 답변에 labeler가 rating
- 2-2) OpenAI 사용자가 rating
- -> RM finetuning dataset (33k)
- 3) SFT가 생성한 답안에 대해 RM이 평가하며 학습 (31k)
- -> PPO dataset (31k)
- Table 1
- SFT baseline이 T0, FLAN보다 NLP task에서 조금 더 높은 성능과 laber에서 선호됌
- InstructGPT는 instruction대로 따라 잘 하는데 GPT-3는 좀 더 조심스러운 프롬프팅이 필요
- 데이터를 만들지 않은 held-out customers (screening test도 제거)로 evaluate했더니 labeler와 같은 선호
- 또한 public NLP dataset에 대해 automatic evaluation
- Figure 1
- InstructGPT는 여전히 간단한 실수를 함
- evaluation
- human preference ratings: quality of each reponse를 1-7의 likert scale로 측정
- public NLP dataset: 1) safety, truthfulness, toxicity, bias 2) traditional NLP task에서 zero-shot 성능
- RealToxicityPrompts dataset에서 human evaluation
- Figure 3
- human preference를 측정
- left: GPT API 사용자의 prompt를 사용함
- right: InstructGPT API 사용자의 prompt를 사용함
- 모델 사이즈에 관계 없이 RLHF가 효과적임
- training labeler와 heldout labeler과 일관된 평가
- prompt의 분포를 바꿔도 결과가 일관됌

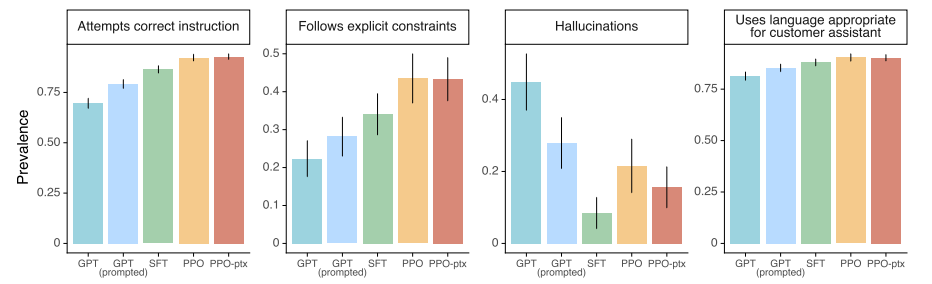
- Figure 4, 5
- 여러 human preference 측정에서 PPO가 Hallucinations를 제외하고 가장 높은 성능을 보임
- GPT: GPT-3
- GPT (prompted): GPT-3 few-shot

- Figure 6
- human evaluation on the TruthfulQA dataset
- color bar: truthfulness and informativeness
- gray bar: truthfulness
- truthfulness는 "I have no comment"와 같이 정답을 모를때도 사실이기 때문에 인정됌
- 두 지표를 비교해 모델이 사실을 얼마나 맞추고, 그 사실 중에 얼마나 충분한 정보를 제공하는지 볼 수 있음

- Figure 7
- Perspective API (유해함을 측정해주는 API)를 활용해 측정함
- InstructGPT가 toxicity하지만 instruction following 능력이 있음
- Respectful: safe하고 respectful하게 출력하라고 instruction을 넣어줌

Discussion
- 대부분의 LLM 연구는 pretraining이었으나 이번 연구처럼 LLM을 Finetuning하는 것은 많은 비용이 듬 -> Alignment 방식은 훨씬 적은 비용이 듬
- 이 때까지 나온 논문 중 가장 효율적으로 사용자 친화적인 모델 학습 방법
- LLM을 finetuning하면 일반화 능력을 잃어버리는 경향이 있는데 InstructGPT는 일반화 능력을 유지하면서도 사용자 친화적
Result
- 1.3B의 InstructGPT 모델이 175B GPT-3 모델보다 선호되는 output을 생성함
- truthfulness하고 toxic을 적게 생성
- InstructGPT는 여전히 간단한 실수를 함
- public NLP task에서 성능 감소가 보이지만 PPO-ptx를 사용하면 원래의 성능과 유사해져 높은 성능을 내면서도 사람의 의도에 맞도록 학습 가능
Limitation
- 모델 학습에 대한 컴퓨팅 자원/ 탄소 발자국 논의가 빠짐
- labeling data 필요
- toxicity는 크게 개선되지 않으면서 Instruction을 잘 따